
Secrets of professionals: how to scale datacenters of cloud providers
You have probably seen many times epic photos from data centers, in which drains clogged with servers go over the horizon, powerful generators and air conditioning systems are installed. Many people like to brag about such personnel, but I have always been interested in how Data center operators choose and configure their equipment. Why, for example, do they install server "A" instead of "B", what do they rely on - the speed of the VM or the potential number of them in the rack, and how do they design computing power, especially in the modern world of hybrid clouds and artificial intelligence? We asked an expert from it-GRAD to tell us about all this.

|
About the author: Nikolay Aralovets, senior system engineer of the it-GRAD cloud provider (part of the MTS Group) according to Wikipedia: It-GRAD was established in 2008. Specializes in providing "cloud" services (IaaS, SaaS) for the corporate sector and government agencies, as well as in the design and construction of private (private cloud) and hybrid cloud infrastructures. It-GRAD is recognized as the first VMware service provider in Russia and the CIS, which gives us the opportunity to lease virtual infrastructure built on the basis of VMware; |
What is the priority: the speed of the virtual machine or the number of VMS per rack?
VM speed without any specifics is an abstract concept that cannot be evaluated without entering the criteria by which it will be evaluated. For example, typical evaluation criteria are the response time of an application that is running on a VM or the response time of the disk subsystem that hosts the VM data. If a customer wants to deploy all of our favorite 1C on a virtual machine, they need gigahertz on the principle of"the more, the better". For such tasks, clusters with high-frequency processors with a small number of cores are allocated, since multithreading and performance of the memory and disk subsystem are not as important for 1C (SAP) as for a loaded DBMS.
The "right" service provider allocates various hardware platforms and disk resources to separate clusters and pools, and places" typical " customer VMS in the appropriate pools.
You can't predict how many virtual machines 1C (SAP) will run on, and where disk resources will be used intensively and you need to plan Flash storage in advance. This comes with time, with the receipt of certain statistics during the operation of the cloud, so providers working in the market for a long time are valued higher than startups. Each provider has its own platform for VM deployment, its own approach to expansion planning and purchasing.

I see a competent approach to sizing based on the definition of a "cube" for a computing node (compute node) and data storage (storage node). A hardware platform with a certain number of CPU cores and a specified amount of memory is selected as computing cubes. Based on the features of the virtualization platform, estimates are made as to how many "standard" VMS can be run on a single "cube". These" cubes " are used to create clusters/pools where VMS with certain performance requirements can be placed.
A "standard" VM is defined as a VM of a certain configuration, for example, 2 vcpus + 4 GB RAM, 4 vcpus + 32 Gb RAM, and also takes into account the reserve for RAM resources on the hypervisor, for example, 25% and the ratio of the number of vcpus to the total number of CPU cores in the cube (CPU over-provisioning). When the reserve limit is reached, planning for the purchase of equipment begins within the pool.
Approach to storage
As for data storage, the "storage node" cube is selected based on cost, capacity, and IOPS per gigabyte - everything is standard here. The optimal choice in the case of a storage node is a configuration where using the maximum possible capacity does not lead to consumption of processor resources by more than 80-85%. In other words, when, with the maximum possible use of the disk volumes of the node, we can get from it the design capacity for the number of IOPS with the specified response time (latency) specified in the SLA.
Also, when selecting storage systems, a number of other parameters are taken into account (access Protocol and data transmission network, binding necessary for switching computing nodes and storage, energy efficiency, and so on, but I highlight as the main parameter - the efficiency of resource loading
Network Infrastructure
Everything depends on the virtualization platform. In the case of vmware, just two or three hardware servers are enough to deploy a full-fledged SDN. in the case of Openstack, you may need to move the SDN functionality to dedicated hardware servers to achieve the required performance. The choice of hardware switches is based on the price-per-port ratio. There are a number of good solutions that, in addition to the ports themselves, provide SDN functionality for virtualization platforms (Сisco ACI, Arista, Mellanox).
The number of switches (and ports, respectively) is determined by the choice of hardware platform. If these are rack servers, it is optimal to place TOR switches (switches installed at the top of the server rack, approx.ed) in each rack and put them in the core of the network, and if a high-density converged platform is selected (for example, Cisco UCS), there is no need for TOR switches.
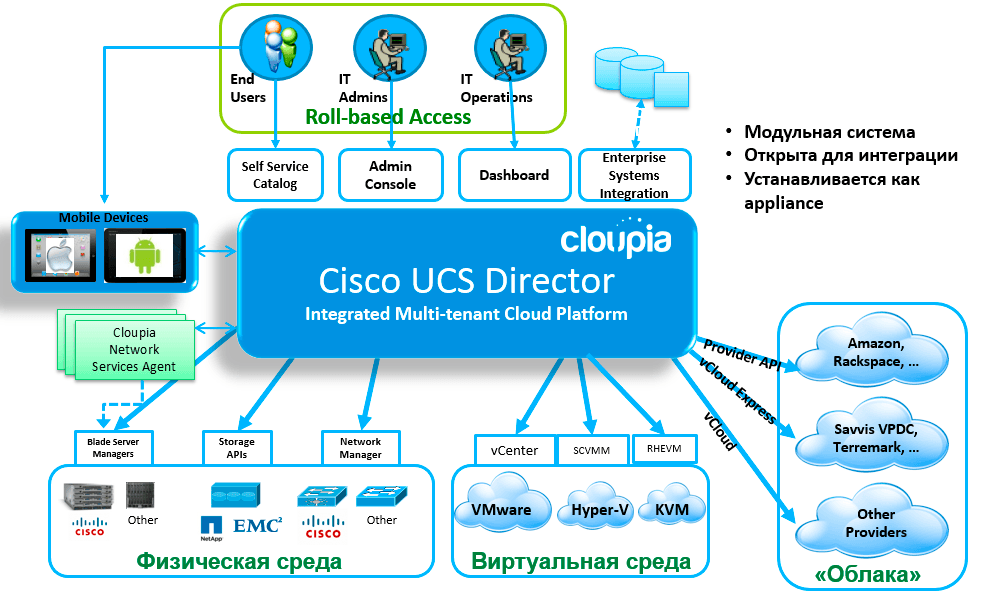
From all the above, the answer to the question "What do you put first: the speed of a separate virtual machine or the number of virtual machines per rack?" it is obvious: the hardware part of the cloud should be designed in such a way that one "cube" contains the maximum possible number of virtual machines that can be placed without compromising their performance.
Saving on licenses
Any major service provider that uses proprietary software applies a licensing scheme in the form of monetary deductions for certain resources, while savings are achieved by using more of these resources (points).
Energy consumption problem
As for energy consumption-here, in my opinion, the problem lies in a slightly different plane. All commercial data Centers rent a "standard" rack with 5-6 kW of electrical power supplied to it. In a number of data centers, this is not a strict restriction, and the customer can consume more power, but in any case there are restrictions on exceeding it, for example, no more than 3 kW. In some data centers, this is a strict restriction, so you probably won't be able to achieve 100% rack occupancy. It would seem that you can take energy-efficient equipment, but, for example, high-frequency processors and multi-socket hardware servers consume a lot of power, so you have to compromise between the power of the "computing node" and the ability to place such "cubes" in one rack. 100% density of equipment placement in the rack with its 75-80% load capacity in practice, unfortunately, is not feasible.
SLA (responsibility to the customer)
The SLA must specify at least the availability of the service (management interface, network/Internet access, availability of disk resources). The values of these parameters on average do not exceed 99.9% for basic components (storage nodes, local network, Internet access channel), which allows downtime of no more than 43 minutes per month.
Of course, more stringent SLA agreements can be concluded: detailed characteristics of a particular service component can be specified separately, such as disk subsystem performance and response time, Internet channel width, channel reservation, etc. Such extended conditions usually require dedicated infrastructure, but these are special cases.
|
HWP: That helps prevent slowdown in a virtual machine? |
|
Nikolai Aralovets | it-GRAD: First, the automatic load balancing mechanisms provided by the virtualization environment, such as VMware DRS and SDRS. They allow you to dynamically balance the load of computing nodes and data storage resources. Secondly, when designing, a certain limit of resource consumption within the pool/cluster is laid, when it is reached, the expansion procedure is launched (purchase of hardware resources and their commissioning). Third, monitoring resource consumption at the hypervisor level. |
The basic principle of siding is that all servers within the resource pool are the same in capacity, respectively, and their cost is the same. VMS do not migrate outside the cluster, at least when they are normally used in automatic mode.
|
HWP: What benchmarks are used for the selection of specifications? |
|
Nikolai Aralovets | it-GRAD: In the case of a data storage node, we use any load generator, and we can also use a benchmark from the manufacturer of virtualization platforms. We calculate the storage utilization rate, the ratio of IOPS per volume, understand that this configuration is suitable for us and start replicating it. In the case of computing nodes, we use empirical methods, siding testing techniques, and utilities from virtualization platform manufacturers (https://wintelguy.com/vmcalc.pl. https://www.vmware.com/products/capacity-planner.html или https://access.redhat.com/articles/1337163) plus your own experience. |
Data center prospects in the next 3-5 years?
Will AMD and ARM push Intel's positions?
The x86_64 processor architecture will remain unchanged in the next 3-5 years and will dominate the cloud computing market. ARM in their modern architecture is definitely not about the cloud, but rather a niche of IoT, integrated solutions, etc. Despite this, for example, vmware supports the ARM architecture for its hypervisor , which is a niche solution that can be used to deploy containers based on VMWare products. In my opinion, Intel will continue to occupy the lion's share of the processor market. From my point of view, AMD is unlikely to be able to displace Intel in the processor market, and this will certainly not happen at the expense of the security features provided by the EPYC platform. Personally, I have always liked AMD (the home platform still runs on a 4-core Phenom:)), but most likely, as in the mid-noughties, the " red " ones simply don't have enough resources to fight Intel.
Will the network infrastructure speed increase?
Speeds of 10/40 GBps are the current reality, within 3-5 years within internal cloud networks, there will be a transition to 25/100 GBps, the need for higher speeds in internal cloud networks is still difficult to imagine. Maximum is the core of a large network. HCI platforms already recommend internal interconnects between nodes at speeds of 100 GBps to achieve maximum performance during I/o operations. Actively continue to develop cloud-based network services, microsegmentation, CDN, and so on .p. In my opinion, the number of proprietary network hardware and network operating systems should be reduced. Open platforms based on Open Ethernet standards will be used for greater flexibility (https://ru.mellanox.com/open-ethernet/), although here again the question of network security will arise..
How will storage systems develop?
In the field of data storage systems, everything is moving towards the final transition to Flash. NVMe will become the basic Protocol for providing block devices to the operating system within 5-10 years. in this regard, the transition to NVMe-of-FC data transfer protocols and NVMe-of-Eth, which is more promising in my opinion, will begin. From the point of view of abandoning expensive "traditional" storage systems from vendors within the clouds, I see a promising transition to distributed file systems (for example, analogs of OneFS). From the point of view of architecture and sales model of "traditional" storage systems, I like solutions from InfiniDat and Netapp, but this is a matter of taste.
Trends in the Cloud
If we take the General trend - the future belongs to those providers who control not only the hardware component of the cloud, but also its software platform (hypervisors, SDN, data warehouses). This is the hyperscale model (Amazon, Google, Alibaba). In Russia, it is trying to repeat Yandex and mail.ru. The General cloud trend is "VM as code", "network as code", "storage as code". Public clouds built on proprietary solutions are quite expensive, given the need for royalties to SOFTWARE manufacturers, but practice shows that they are in demand (VMware vSphere as a service is successfully sold by Amazon). Almost all Russian service providers use VMWare products as a virtualization platform and for providing self-services.
Security trends
It seems to me that the requirements of GDRP (FZ-152) and PCI-DSS will be implemented within dedicated cloud segments. Within these segments, there is a high probability that, for example, hardware encryption technologies for memory and processor caches will be implemented. An attempt to extend such technologies to the entire public cloud may lead to an unjustified complication of its maintenance, loss of flexibility in terms of self-services, and the introduction of a number of restrictions, which in turn will lead to an increase in the cost of the provider's services. If the technologies of hardware encryption of data in RAM quickly reach maturity (there will be support from both hardware component manufacturers and major operating systems) I don't see any problems integrating them into the public cloud, but again, everything will depend on the cost of such integration. Currently, 90% of cloud users simply do not need such technologies.
Parting words
Do not forget that before purchasing the service, the customer can evaluate the speed criteria by taking the VM for a test to check the ping time to the data center where the provider's site is located and its connectivity to the outside world,evaluate the performance and response time of the disk subsystem that hosts the VM, the time for executing requests within the application that can be deployed on a test virtual machine, and so on.
Nikolay Aralovets
17/09.2019












