
Neuromorphic future: an attempt to put the brain in the server
Until today, processor manufacturers have been forced to follow Moore's law in order to produce a new generation of chips with higher performance and lower power consumption. In our time, the picture of the world has changed. Research around the world suggests a wide variety of architectures that are more productive and consume less energy. In this article, we will talk about alternatives and reasons why one of these technologies can be more profitable than the outdated Moore's law and how it can lead to a huge leap in the development of the industry.
What is Moore's law? Its sunset
Moore's law, or as it is also called – the Savior of all processor manufacturers around the world – was invented by Dr. Gordon Moore, the founder of Intel, in 1965. The law States: "The number of transistors in a chip should double every 2 years." Why was it called that? This law affected the semiconductor industry so much that "people did not hesitate to buy a new model of the best processor in its category, being fully confident that it would be better than the previous one," said former Intel engineer Robert P. Colwell. In the past, programs with low performance were not a problem, as software developers hoped that they would be saved by Moore's law.
The problem we are talking about today is that the law is on the verge of death (read the article "Smart chips will smooth out the rejection of Moore's law in data centers")! Or as Henry Samuels, Broadcom's technical Director, puts it: "it's gray, it's getting old, it's not dead, but you have to send Moore's law to a nursing home (AARP)."
The closer we get to atomic size in microchip manufacturing, the harder it is for manufacturers to reduce the size of transistors. This fact has greatly affected the industry. Intel, in 2015, said that a new generation of chips will be released every 2.5 years, it also indicated that transistors will only be able to continue to decrease for the next 5 years.
What led to the death of such a long-lived law? - Quantum Mechanics! Let's go deeper into the processor: we all know that it only understands machine code. Regardless of what it saves or executes, it is all represented as 1 and 0. These 1 or 0 States are stored by logic blocks, which in turn consist of transistors. The work of transistors is to regulate the flow of electrons (by creating a potential barrier) so as to hold a certain state in the logic gates. Now, when we go down to the scale of 1 nm = 10 atoms, it becomes difficult to regulate the flow of electrons. Even if there is a potential barrier, the flow of electrons continues due to a phenomenon called Quantum tunneling. As a result, current leakage increases significantly, making the architecture inefficient.
Alternative technology
Big companies, as well as scientists, are trying to get around this problem so as not to end up at the bottom of the industry. Intel's advanced development teams expect the company to adapt new transistor materials and structures to better control the passing current. With the growing popularity of machine learning, as well as a variety of new and complex algorithms, the requirements for processors that could perform complex calculations have increased.
Scientists around the world are working in such areas:
- Quantum Computer: it uses the ability of a subatomic particle to exist in more than 1 state at any given time. Unlike regular bits, which can store either 0 or 1, quantum bits (quits) can store much more information. This means that a quantum computer can store much more information than a normal computer, while consuming less energy.
- Carbon nanotubes: These are microscopic sheets of carbon rolled into cylinders, actively studied by IBM. In a paper published in the journal Science, they describe a new way to create transistors using carbon nanotubes, which can be significantly smaller than the silicon transistors we have today.
- Parallel architectures: this approach has been widely used over the past decade to circumvent the performance barrier. Highly parallel architectures (GPUs) are being developed to perform simultaneous operations. Unlike the John von Neumann architecture, which executes instructions sequentially on a single core, the GPU has parallel threads running on multiple cores, which significantly speeds up the process. The focus is also shifting towards an energy-efficient FPGA to replace the GPU.
- Neuromorphic equipment: includes any electrical device that mimics the natural biological structures of our nervous system. The goal is to give cognitive abilities to the machine by embedding neurons in silicon. Due to much better energy efficiency and parallelism, this chip is considered an alternative to traditional architectures and "energy-hungry" GPUs.
Neuromorphic equipment
The human brain is the most energy-efficient and fastest delay system on Earth. It processes complex information faster and much better than any computer. This is largely due to its architecture, which consists of dense neurons that efficiently transmit signals through their synapses. The goal of neuromorphic engineering is to implement this architecture and performance in silicon. The term was coined by Carver Mead in the late 1980s, describing systems containing analog/digital circuits that mimic the neurobiological elements present in the nervous system. Many research institutions have invested in developing chips that can do the same.

DARPA 16 TrueNorth chips neuromorphic adaptive plastic scalable electronics (SyNAPSE) system. Each chip has one million silicon "neurons" and 256 million silicon synapses between neurons. Source: IBM Corp
The IBM - True North neuromorphic chip has 4096 cores, each with 256 neurons, and each neuron has 256 synapses to communicate with others. Architecture, being very close to the brain, is very efficient in terms of energy consumption. Similarly, Intel's Loihi boasts 128 cores, each core having 1024 neurons. The APT group from the University of Manchester recently discovered the world's fastest supercomputer, SpiNNaker, consisting only of neuromorphic cores. Brainchip is another company developing similar chips for data processing, cybersecurity, and financial technology applications. The Human Brain Project is a large-scale project funded by the European Union, which is looking for an answer to the question of how to create new algorithms and computers that mimic the work of the brain.

All these systems have one thing in common – they are all highly energy efficient. TrueNorth consumes 1/10, 000 of the specific power of a regular John von Neumann processor. This huge difference is due to the asynchronous nature of processing on a chip, as in the human brain. Each neuron does not need to be updated at each step. Only those that are in action require energy. This is called event-oriented processing and is the most important aspect for visualizing neuromorphic systems as a suitable alternative for conventional architectures.
Neural network with "spikes"
A dense network of neurons connected by synapses on a neuromorphic chip is called A "spiking Neural Network". Neurons interact with each other by transmitting impulses through synapses. The aforementioned chips implement this network at the hardware level, but much attention is paid to modeling it in software, as well as to evaluating performance or solving problems with pattern recognition and other machine learning applications.
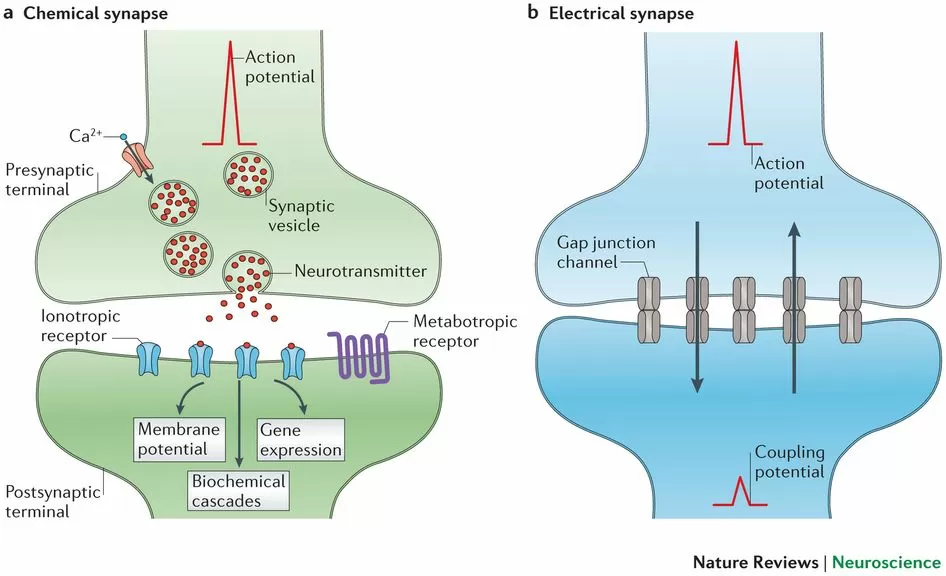
At first, all this may seem esoteric and takes time to understand the network dynamics of SNN. Since this technology is still under development, the available documentation is not sufficient to fully understand it.
This blog series aims to develop an understanding of SNN from scratch with each element of the network explained in detail and implemented in Python. We will also discuss existing Python libraries for SNN.
Ron Amadeo
11/02.2020












