
The new memory addressing scheme in IBM Power10 will change the way we look at AI applications
IBM's lead engineer, bill stark, asks the question: "what if there is a new kind of workload and I want to collect much more memory than could ever fit in a single device? This is a completely new application: what if I want one computer to talk to a petabyte of memory? But today, no one knows how to build such a system."
With a concept called distributed memory disaggregation applied in the latest IBM Power10 processors, "you can really use huge, huge amounts of memory and allow whole new types of workloads to run on computers running in a single cloud."

In the new IBM Power 10 processors, the company has rethought the approach to working with RAM, and now, for example, one processor core of one server can address physical memory installed on another server located in the same cluster. This is achieved through architecture features where multiple cores sharing a common memory address space can be combined to perform common tasks in parallel that would require asynchronous accelerators such as GPUs, ASICs, and FPGAs to use much more threads, as well as a separate orchestration scheme.
Today, GPU accelerators are tied to their own server. They perform highly recursive algorithmic tasks much faster than a normal processor, whose concurrency threads are limited by the number of available cores. Although IBM has had a hand in developing accelerator technology, most recently supporting the OpenCAPI architecture for accelerator interfaces, it does not have the same market shares as Intel (after buying Altera in 2015), Nvidia, or Xilinx.
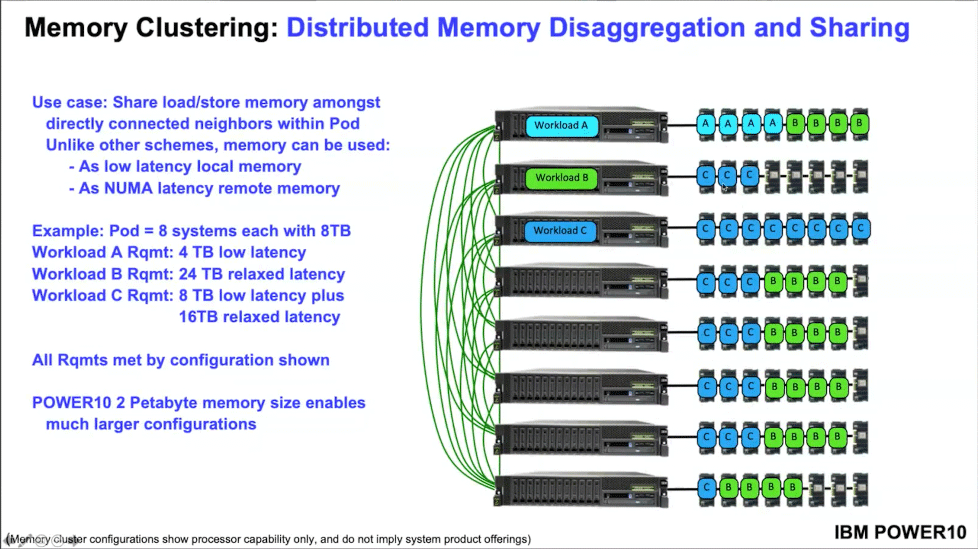
With the new approach to memory architecture, many types of resource-intensive computing will not require the use of asynchronous accelerators, including GPU. the AI block will work according to the classic SMP scheme, which is more friendly for programmers than development for GPU or ASIC. Various AI tasks can be integrated into the General flow of program code, which in turn will not prevent any large-scale tasks for AI processing to be transferred to separate accelerators (GPU or ASIC). This will allow you to return AI tasks to a sequential, synchronized, symmetrical workflow on the CPU.

IBM intends to take full advantage of its Red Hat division by making OpenShift, its commercial Kubernetes platform, a workload deployment mechanism. This means that the Power10 cluster will be able to organize highly parallelized workloads — perhaps not very parallelized, but still somewhat complex-into a single group of tasks managed through Kubernetes, rather than through some external engine.
Ron Amadeo
25/08.2020












