
Lenovo ThinkAgile VX3320 review - a hyperconverged solution for simplified enterprise-wide vSAN deployment
The ideology of hyperconvergent solutions using VMware technologies has its advantages: this is a relatively low cost at the start, and the ability to scale almost infinitely by increasing the number of nodes up to 64 pieces per cluster and increasing the number of clusters under unified management, and uniform distribution of storage and computing resources with periodic rebalancing to maintain high performance, and fault tolerance of the type N+1 or N+2 (and even N+3, but only for RAID-1 (Mirroring) policies), and the ability to apply all these advantages individually for each virtual machine, depending on the data protection requirements put forward.
|
“Hyperconverged systems are rapidly gaining popularity and are already becoming the standard for building virtualization platforms in the corporate environment. Our project implementation experience demonstrates many advantages of hyperconvergent systems, especially in comparison with outdated approaches. This is a start with a minimum volume and a linear increase in system performance indicators as the number of nodes increases, simplification of infrastructure management, the fastest possible adaptation of new software and hardware technologies (for example, support for the latest Intel Optane P5800X storage modules). Ultimately, hyperconverged systems make it possible to build a horizontally scalable IT infrastructure with a large margin of” strength", flexibly plan the IT budget and significantly improve the efficiency of IT resource management. Our company SoftwareONE has broad competencies in the implementation of turnkey projects, including those based on Lenovo solutions – from design to implementation and maintenance. To conduct pilot demonstrations and pre-project tests, we have created a test stand based on the Lenovo ThinkAgile VX hyperconvergent platform, which has proven itself to be a high-performance and reliable solution”. |
 Dmitry Starkov, Head of Infrastructure Department, SoftwareONE (
Dmitry Starkov, Head of Infrastructure Department, SoftwareONE (With the upgrade to version 7, the VMware vSphere platform has received an important element of the vSphere LifeCycle Control Manager, designed to facilitate the maintenance of the existing infrastructure up to date and automate the installation of updates. The architecture of this solution provides for the active participation of the equipment manufacturer in the lifecycle control process, at a minimum, vendors now create their own repositories with firmware for the components of the supplied systems, and at a maximum-offer the customer pre-configured and ready-to-start solutions optimized specifically for deploying a VMware vSAN cluster. Today we will consider such a solution from Lenovo, a model of the ThinkAgile VX series.
Since in hyperconverged vSAN clusters, the interaction between nodes is carried out via an Ethernet network, the "best practices" recommend using the following scheme with fault-tolerant switches. As a rule, two high-performance switches of the Top-of-Rack (ToR) class with SFP+ slots for a copper DAC connection or optics are allocated to the data transmission network. Separately, there is a network of BMC controllers (XCC - XClarity Controller for hardware monitoring and console access to nodes).
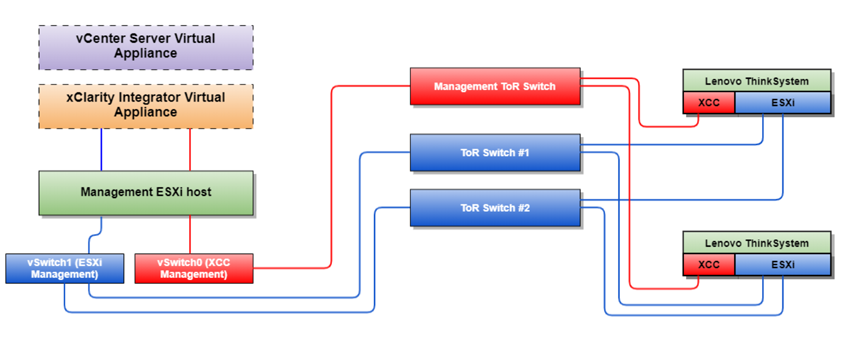
It should be noted that the software-defined network configuration of vSAN has sufficient flexibility, and allows you to manage a pair of switches for the vSAN, vMotion, Management and others using the separation of networks into logical VLANs, and moreover-already during operation, you can change network settings without stopping services on running virtual machines.
Advantages of the factory configuration
The VMware ESXi software has a limited list of supported hardware, and it is possible that during the operation of the node, after an update, any physical device in the server stops starting at all. The most famous such case was the sad update ESXi 6.7 U2 build 13006603, which disabled support for" non-server " NVMe drives, which were often used in self-assembled configurations and were not present in the VMware compatibility list (HCL). In order to restore the functionality of the servers, many system administrators were forced to reinstall the operating system with a rollback to an older version, evacuate the VM, and only then change the non-working drive and install the update.
It is quite simple to insure against such unpleasant surprises - you need to make sure that the selected equipment is compatible with VMware products in general, vSAN technology in particular and is integrated into the new vLCM update system. A large manufacturer of server equipment can afford not only to release an optimized configuration of servers for vSAN, but also to take into account the compatibility list of VMware at the stage of online configuration of virtualization nodes for their needs. In other words, to provide an opportunity to install only those drives and those expansion cards that are tested for compatibility with vSAN.
Lenovo has applied all these steps to the ThinkAgile VX3320 series, which is delivered as a specialized hardware and software package for fast deployment and easy maintenance of vSAN clusters. While preserving the advantages of software-defined environments, such as the ability to configure nodes to suit your needs, the Lenovo ThinkAgile VX series offers solutions for both AMD EPYC-based infrastructures and Intel Xeon-based clusters. In total, the ThinkAgile model range includes 7 models in the format from 1U to 4U, including models with GPU support and support for 4 Intel Xeon processors.
Design of computing nodes
We received a demo kit for testing, consisting of 4 ThinkAgile VX3320 nodes, each of which is a modified version of the Lenovo SR630 Gen2 server in 1U format and has two Intel Xeon Scalable processors of the second generation.



Devices modified for vSAN differ from a regular server in the absence of a diagnostic panel and a port on the front panel. This is a common feature for the entire ThinkAgile series, but otherwise the device can be completely reconfigured to meet the needs of a specific customer.
In our case, each node has a pair of 10-Gigabit RJ45 ports based on an Intel x722 controller and two 25-Gigabit Ethernet SFP+ ports on the Mellanox ConnectX-4 expansion board.


In All-Flash vSAN clusters, support for 10-Gigabit network adapters is mandatory, but the All-Flash cluster also gives its advantages - the use of RAID-5 (Erasure Coding) , RAID-6 (Erasure Coding) data storage policies (in configurations of 4 or 6 computing nodes, respectively), as well as to support deduplication and compression technologies (starting from vSphere 7, only compression mode can be used). All-Flash cluster, implies the use of only SSD drives for both the Capacity Layer and the data caching Layer.


For the disk subsystem in the servers under consideration, 10 compartments are allocated for 2.5-inch drives 15 mm high of the U. 2 type with a PCI Express bus, 6 of which are connected via a pair of ThinkSystem 1610-4P NVMe switch adapters, and four are directly connected to processors. In this case, it should be borne in mind that, unlike SAS/SATA drives, for which HBA interface controllers were used, for the operation of drives with the U. 2 interface (PCI Express with the possibility of hot swapping), switch boards are used, the impact of which on the I/O delay is minimal, or even reduced to zero.




Today, processors for such boards are developed by Broadcom, which at one time bought the largest manufacturer of disk controllers, LSI. An interesting feature of the All-Flash design is the absence of BBU (Battery Backup Unit) modules, since the task of saving the local cache in case of a power failure is solved by each SSD individually, due to the built-in capacitor banks.


Our test servers were configured based on two disk groups per node. For the Capacity layer, Intel P4510 series drives with a capacity of 2 TB are used, and for the caching layer - Intel Optane P4800X with a capacity of 375 GB. The first ones were connected via a switchboard, and the second ones were connected directly to the processors. It should be noted that the presence of two disk groups in a node allows you to increase the cluster's fault tolerance in case of a drive failure, as well as to achieve higher speed under certain conditions when the disk load is programmatically distributed between the drive groups. At the same time, it should be borne in mind that in All-Flash arrays, the caching layer works only on write operations without differentiating between sequential and random access.

To install the operating system, two SSD formats are installed on each server.2 with a 240 GB mSATA interface. They are combined into a RAID array and are available in the UEFI shell of the console administration. The VMware ESXi hypervisor has already been deployed from the factory on the servers, so to put the system into operation, you just need to connect the cables and press the Power button.







Evaluating the build quality of ThinkAgile VX servers, I would like to say that many technical solutions here are aimed at facilitating administration at the place of installation of equipment. Each machine can be disassembled with bare hands without using a screwdriver, the levers that need to be pulled are indicated in blue, and the components that can be changed "to hot" are dark orange. The latter include SSDs, fans and power supplies.

The test servers received by us at the Moscow office of the HWP test laboratory were configured as follows:
- Two Intel Xeon 6226 processors (16 cores, 32 threads, 2.9-3.9 GHz, 22 Mb cache).
- 256 GB DDR4-2933
- 6x Intel P4510 drives with a capacity of 2 TB each
- 2 375 GB Intel Optane P4800X drives
- 1x 25Gbps Mellanox ConnectX-4 Ethernet Controller (2x SFP+)
- 1x Intel X722 controller (2x 10GBase-T)
- 2x 1100 W power supply units.

Taking into account such high energy consumption, it should be borne in mind that, in the end, the costs of power and air conditioning in hyperconvergent configurations are lower compared to traditional schemes with consolidated storage systems. The savings are achieved by using shared cluster resources shared for computing operations and maintaining a distributed data warehouse. You can read more about this saving in the study from VMware (link to the document).
Mass installation using Deployer VX
By itself, the process of configuring a vSAN cluster is relatively labor-intensive, but to facilitate the deployment of a large number of servers, Lenovo has developed the Deployer VX tool. This is the software that comes in the form of .ova applications based on CentOS 7, designed to be installed on the managing host or even on the administrator's laptop. By the way, by default, this software is already deployed on ThinkAgile VX servers, which are now supplied with the installer (read user manual).
When you first start Lenovo Deployer VX, it automatically finds all Lenovo ThinkAgile VX nodes in the network, including their BMC controllers. After selecting the necessary servers to combine into a vSAN cluster, the user then goes through the simple steps of basic cluster configuration using the installation wizard, resulting in a configured cluster with all the administration elements, with the specified IP addresses and logins/passwords.
Similarly, without having to configure each host individually, Deployer VX can expand an existing vSAN cluster by adding ThinkAgile VX servers to it.
Lenovo XClarity Integrator and Lenovo XClarity Administrator
As already mentioned, starting with version 7 of ESXi, VMware has optimized the installation of patches and drivers for hardware, delegating these powers to hardware manufacturers. A separate repository has been created for Lenovo ThinkAgile and ThinkSystem systems, through which firmware updates for server components are delivered. You can install them through additional software, namely, through Lenovo XClarity Integrator, which is a plug-in module installed as a small virtual machine (. ova template) and connected to the vCenter management host.
Thus, the process of updating firmware and hardware drivers does not go beyond the vSphere Client management interface, which greatly facilitates the work of system administrators: the search for fresh drivers on the manufacturer's website is forever a thing of the past.
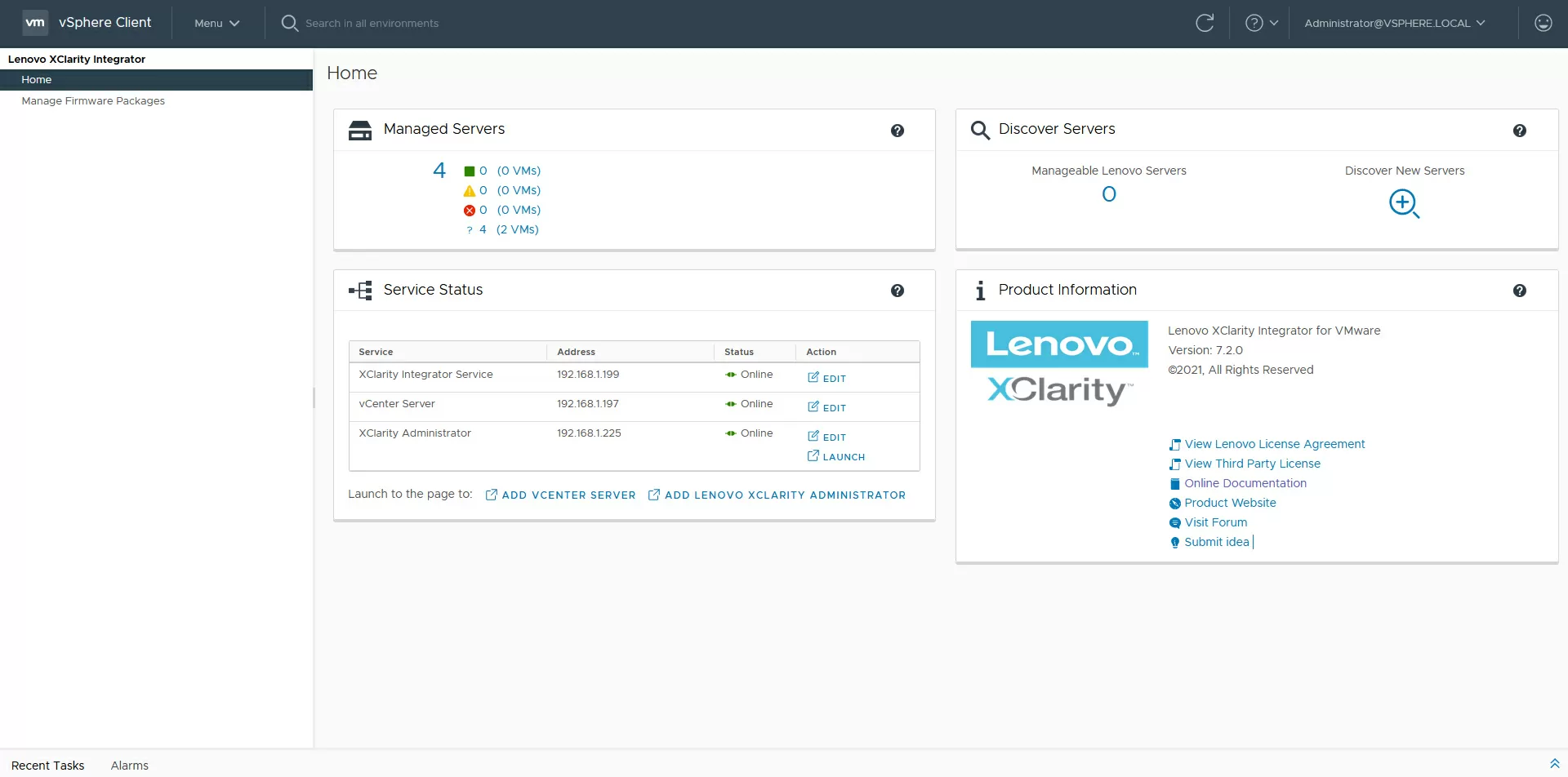
One of the functions of the "integrator" is interaction with BMC server systems, XClarity Controller, for importing hardware monitoring data and equipment inventory in the general vSphere Client interface.
To implement the possibility of forcibly restarting servers from the cluster, for example, to update the UEFI of the motherboard, XClarity Administrator is used.
The process of adding a large number of servers to the management system is so automated that the installer does not even have to enter a login/password when connecting to each server.
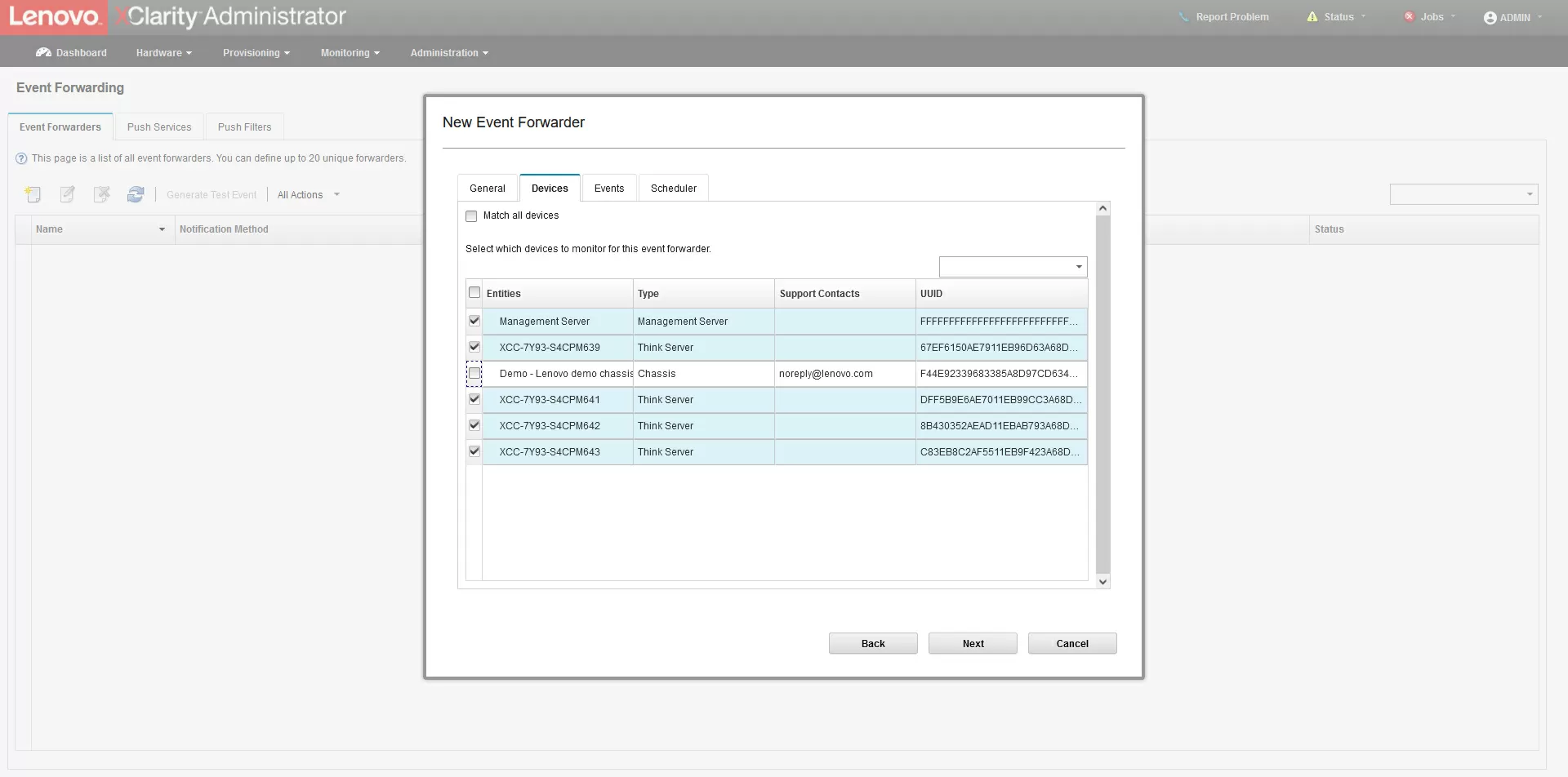
It is worth adding that XClarity Administrator supports not only servers, but also switches, computers, storage and other Lenovo equipment.
Integration into the Lifecycle Manager
At its core ,the "Lifecycle Manager" is a system for updating hosts for vSphere, which implements a radically new approach to servicing server equipment. If earlier the state of the software was controlled individually for each host and in one situation or another there could be deviations in the versions of the drivers and OS images used, which inevitably led to confusion, today the unification of the image, drivers and firmware for the vSAN cluster is taken as a basis, and this point should be disclosed in more detail.
As mentioned above, each Lenovo ThinkAgileVX host from the factory comes pre-installed with ESXi, including tested drivers for server components. When building a cluster, the first question that is asked in the vCenter interface is "do you want to import a server image from the host being added in order to use it for all nodes in the cluster"? It is recommended to agree if homogeneous nodes are used, as in our test equipment. The selected image is copied to the vCenter host, and its settings are applied to all nodes in the cluster. In the future, with planned software updates, vCenter, or rather vLCM, already focuses on this universal image used in the cluster, and each update of each vSAN host completely repeats the same update on another vSAN node.
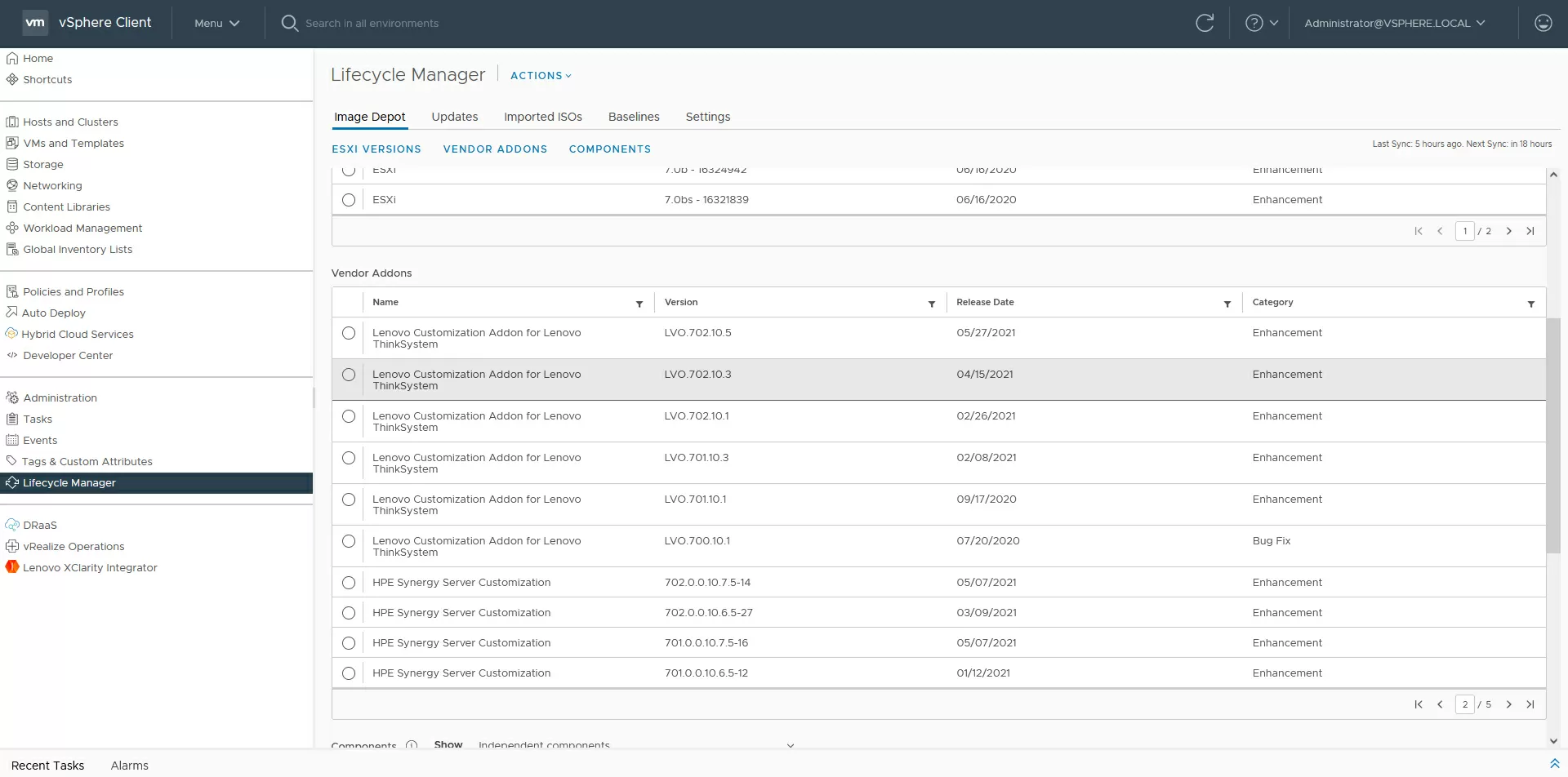
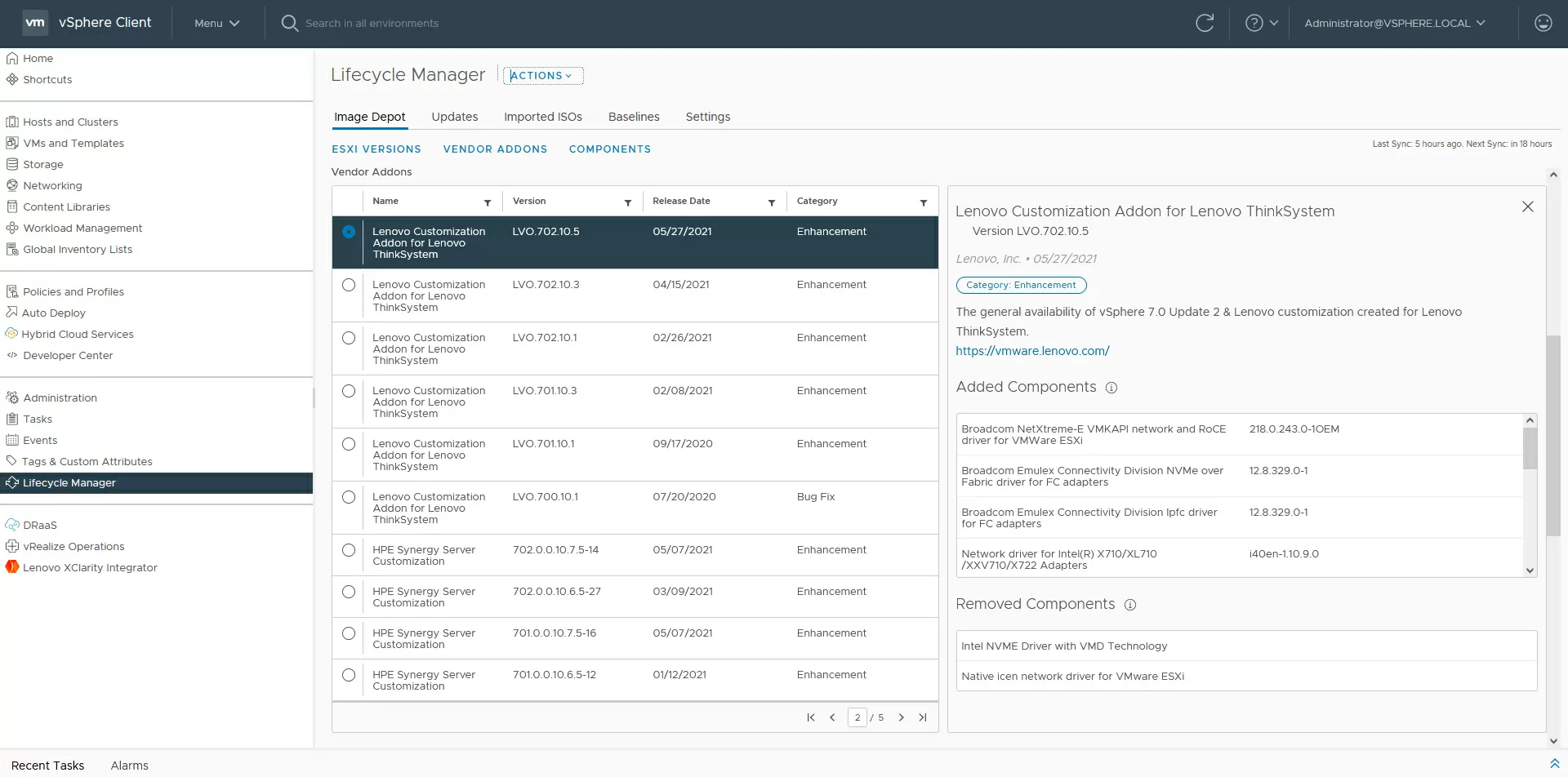
In addition to keeping the software up-to-date, vSphere Lifecycle Manager constantly checks the hardware compatibility lists, but in this particular case, the integrator or equipment owner delegates compatibility issues to Lenovo, since ThinkAgile VX is delivered not as a "server compatible with VMware", but as a software and hardware complex, in which VMware technologies are an integral part of it.
- Any variants of non-compliance with the identity within the cluster are excluded.
- Errors related to the commissioning of a machine with a different operating system image are excluded.
- Operations for self-updating drivers are excluded
- Interruptions of the company's services related to software updates are excluded
- Problems in which the hardware lost compatibility after the update are excluded
- Tasks related to manual image assembly and manual configuration of servers are excluded
Scale-out
Most experts are sure that it is impractical to scale the vSAN cluster up, and the right way is either to expand it by adding additional servers to the general cluster, or to create another cluster within the existing or new infrastructure, but in this case it will be necessary to immediately purchase 4 new nodes, which can be expensive. How to do the right thing - there is no single answer, but you can use the VMware vRealize tool to evaluate the interaction of your entire infrastructure both inside the vSAN and outside the cluster, to understand how different elements are coping, and whether there are bottlenecks.
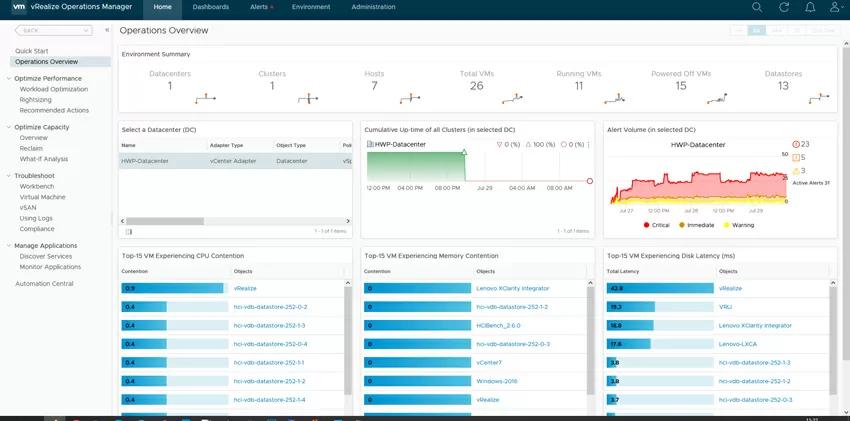
The output and processing of logs from VMware ESXi is configured via the native VMware vRealize Log Insight tool. This is a control panel with clear visualization that allows you to navigate through the logs and metrics of your VMware ecosystem. Data is transmitted to the system from both vCenter and Lenovo XClarity Administrator. The setup process is almost completely automated, and the only thing that needs to be done is to install a package with log descriptions for Lenovo systems from the VMware marketplace.

In general, the visual representation of metrics on a timeline can become an invaluable tool when investigating incidents, planning operations to adjust or modify network connections, scaling or upgrading equipment.
Understanding the performance of a vSAN cluster
In terms of disk performance, the vSAN cluster has an Achilles heel - huge overhead losses associated with the operation of virtual disks and synchronization between nodes. The scale of these losses is shown in the graph below, where the results of the same test are displayed on the same Lenovo ThinkAgile VX node on the fastest of the installed SSD drives, Intel P4800X of the Optane family for Windows Server 2019. The tests were conducted first on bare hardware, then in a virtual machine in the ESXi 7.0.2 hypervisor, and then in a cluster with a RAID 5 storage policy (Erasure Coding).
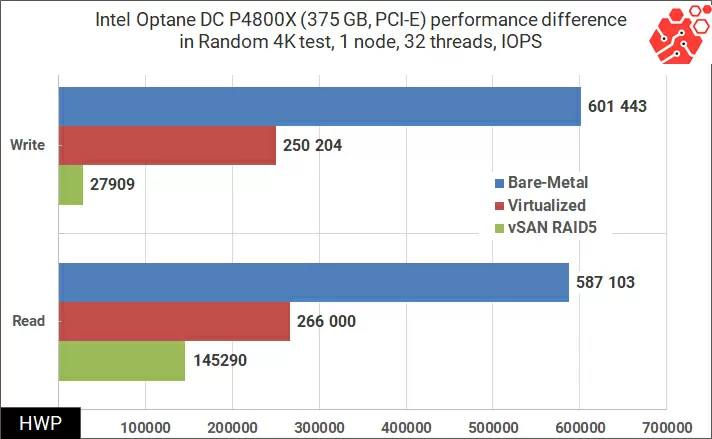
As you can see from the graph, any application with an intensive load on disks running in a virtual environment may encounter increased delays in write operations, which will invariably lead to a drop in overall performance and responsiveness of the service. The reason for this behavior is that for each I/O request, ESXi software performs additional calculations, creating unnecessary delays, and unfortunately this is a software feature that does not depend on the hardware.
But the good news is that when parallelizing loads, requests for" I/O " of the disk subsystem are processed asynchronously and fall into these delays created by the hypervisor, as a result of which the overall speed of the cluster is leveled, and the performance of disk groups begins to add up. If the storage policy in vSphere Client is set to divide VMDK files into strips, then each virtual machine will use from 1 to 7 SSDs (depending on the number of strips) for each virtual disk, and parts of one VMDK can be located on one or on different servers.
The cluster storage system really reveals itself when testing cumulative performance for N-number of virtual machines: providing smooth load distribution between nodes, disk groups and SSD drives. Taking into account the fact that caching in All-Flash disk groups occurs only when writing, the maximum performance should be shown by arbitrary read operations in large blocks.
For testing, we used 16 VMs of the following configuration, located in a vSAN cluster:
- 8 vCPU
- 8 GB RAM
- 200 Gb Test disk, Thick provision
- Debian 9 (boot configuration: noibrs noibpb nopti nospectre_v2 nospectre_v1 l1tf=off nospec_store_bypass_disable no_stf_barrier mds=off tsx=on tsx_async_abort=off mitigations=off)
- VDBench 5.04.06
We will test for the RAID-1 and RAID-5 storage policies with compression enabled and dividing each VMDK into 6 strips, and we will start by measuring the overall latency of the disk system.
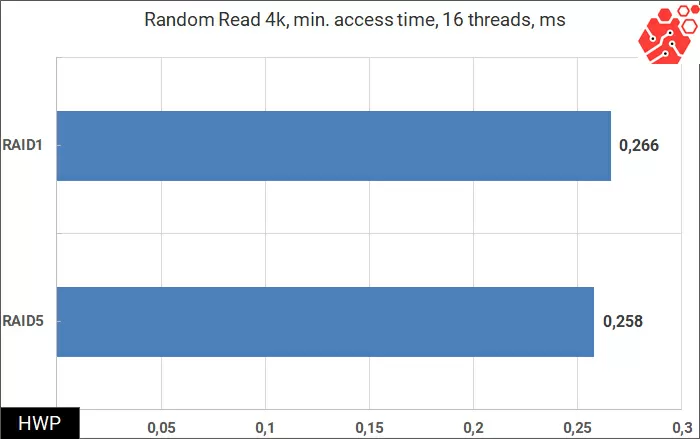
By themselves, the access time figures at the level of 1/4 millisecond look impressive, and if your company's policy is to maintain the storage response time below 1 ms, then a cluster of four ThinkAgileVX meets this condition even with a multithreaded load. Although, what is 16 threads for 4 nodes with 128 physical cores? Let's start gradually increasing the number of threads to 32 for each virtual machine (a total of 1024 threads per cluster), until we run into a delay of 1 ms.
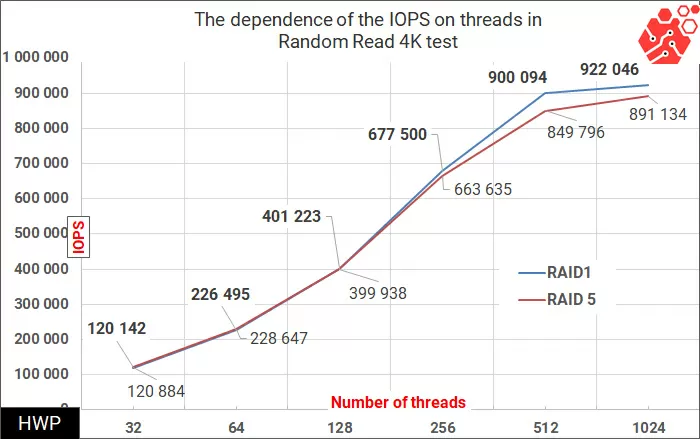
Quite a bit, the cluster does not reach 1 million reads, but the numbers are so impressive. The change in the delay during reading has a parabolic character on the graph, which is characteristic of both hardware storage systems and single disk drives, and which tells us about the absence of some kind of bottleneck in the behavior of the storage system.
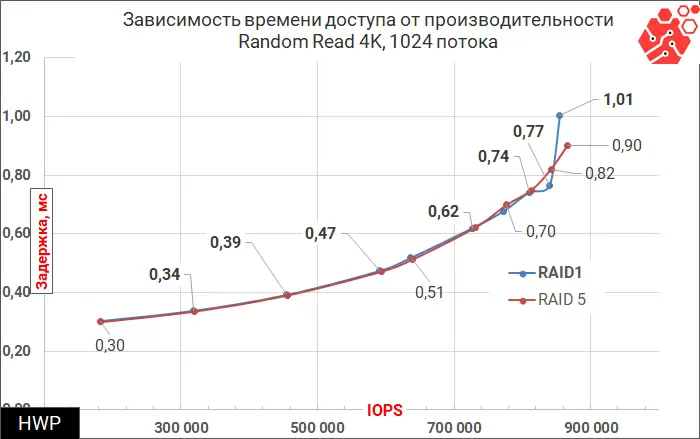
If we talk about comparing RAID-5 and RAID-1, there is practically no difference in most of the tested range, which is achieved by cutting virtual disks into a large number of strips (128 per test configuration), but in recording tests the picture is fundamentally different.
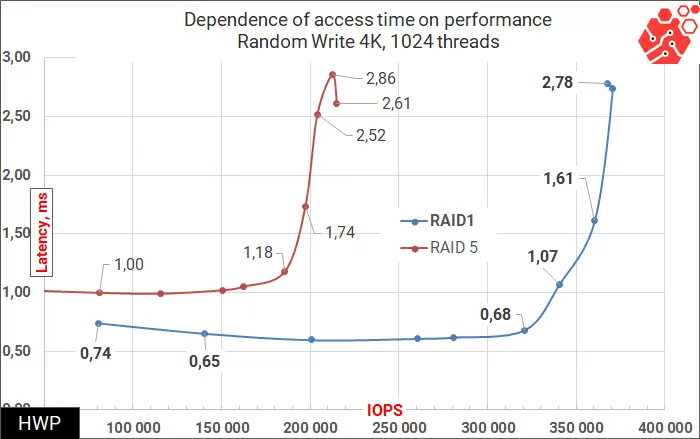
Here, the physical limitation is the interconnects between nodes and additional operations related to the synchronization of blocks between nodes in RAID-5. The same behavior of the cluster is preserved in sequential access operations.
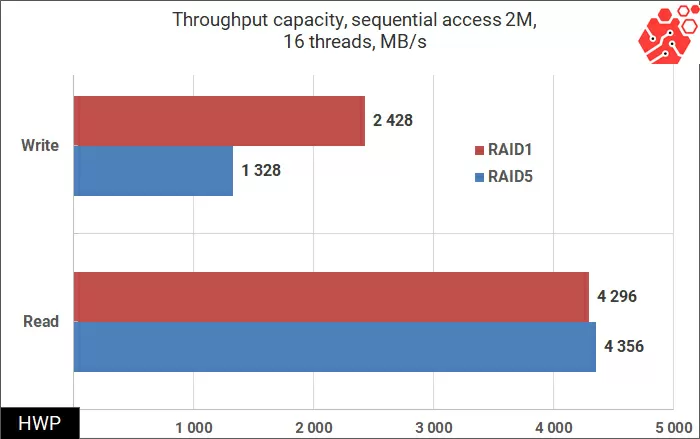
and in random access operations in large blocks of 64 KB, where the speed record in our test is predictably achieved:
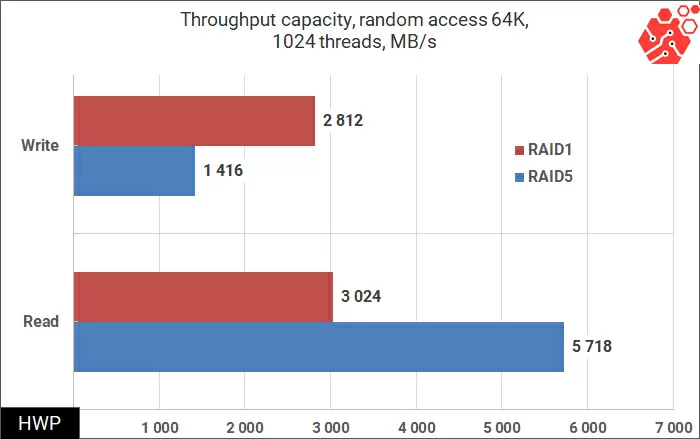
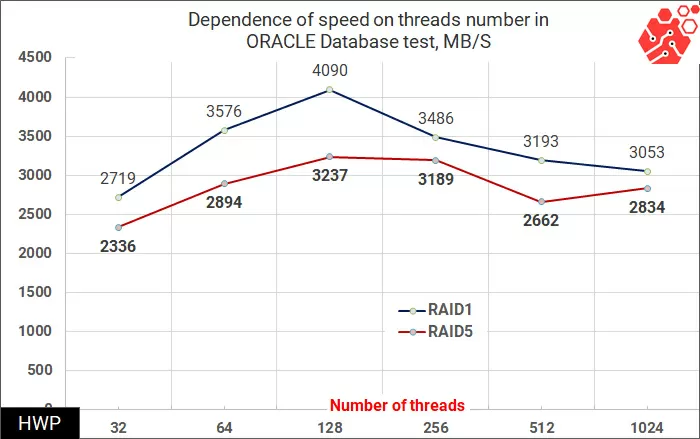
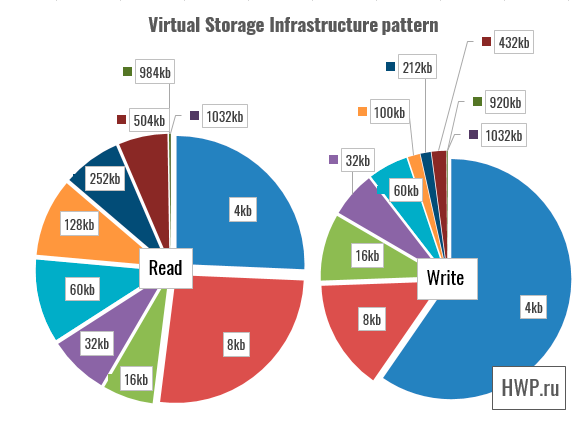
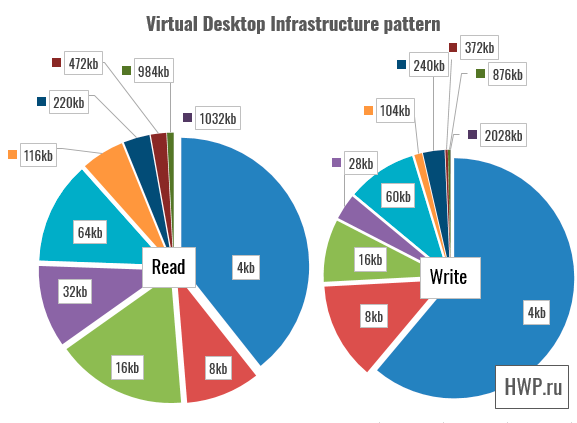
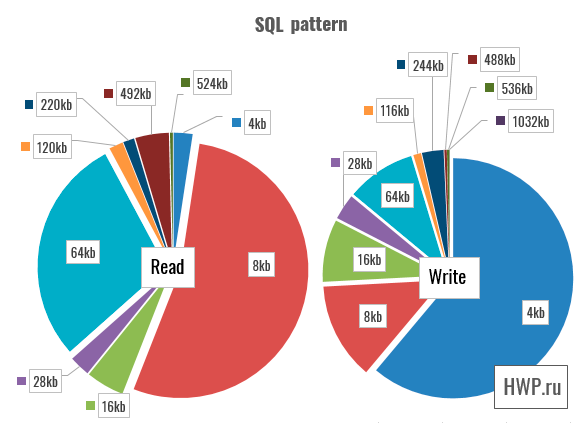
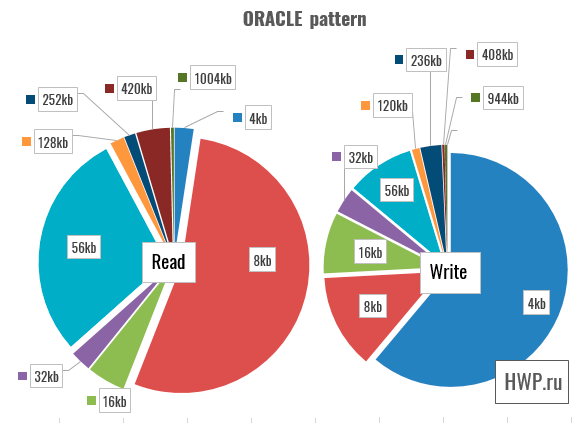
Synthetic tests show that write operations for virtual machines using RAID-5 are difficult for a vSAN cluster, but is this really such a big problem? Not every application uses only a random entry. To answer this question, we will use patterns taken by Pure Storage specialists for four types of load: VSI (Virtual Storage Infrastructure), VDI (Virtual Desktop Infrastructure), SQL and Oracle Database.
In these patterns, disk operations are performed in large blocks, so we choose the total bandwidth as the basis for the assessment.
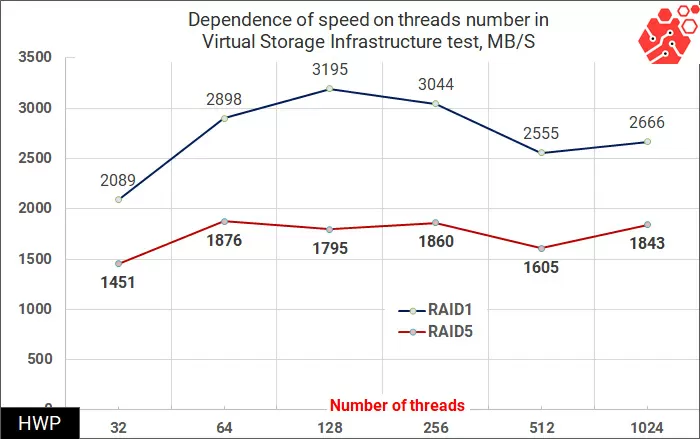
Here, the speed is summed up for read and write operations, so the faster RAID-1 is one and a half times faster than RAID-5, reaching a speed of 3.1 GB/s.
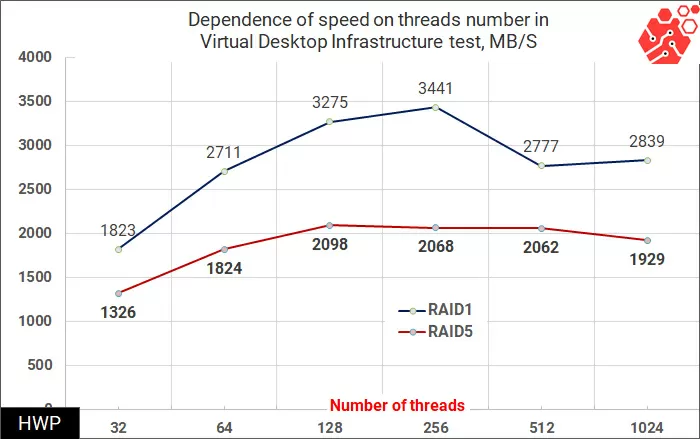
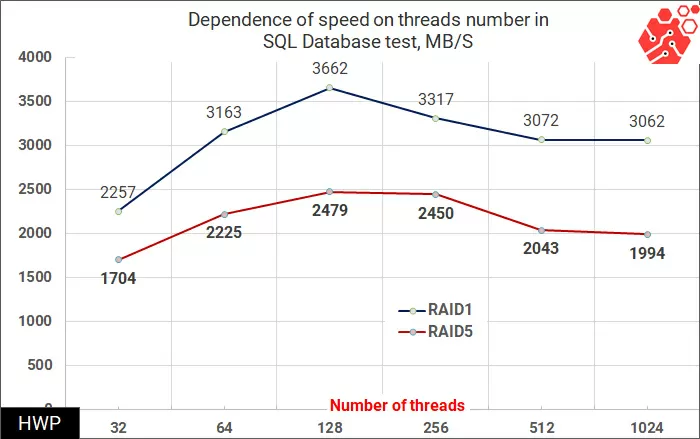
In tests of SQL and Oracle database patterns, the gap is reduced, and in the most complex setting - Oracle 1024 Threads is reduced to a value that can be ignored.
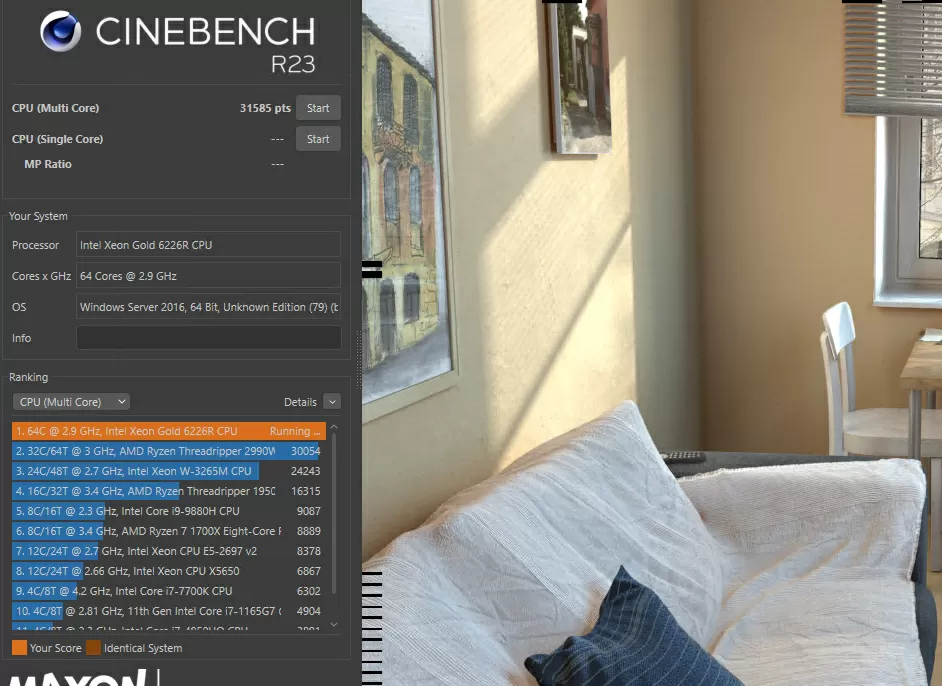
Of course, data storage is an important, but not the only function of vSAN. The powerful computing part of the cluster does not suffer from the overhead associated with virtualization, and if some application needs the maximum performance of 1 core or 32 cores, it will get it, which is confirmed by the Cinebench R23 benchmark in tests for rendering a complex 3D scene. One ThinkAgile VX node sets a small local record, and if the task is to virtualize the post-processing of DCC/CG applications, here is an excellent example of a suitable configuration.
Here I would like to add that in case of a shortage of local resources and the application of the policy of using hybrid clouds in the company, VMware Cloud Foundation (VCF) can be used to deploy additional services. This solution combines VMware vSphere 7, VMware vSAN, VMware NSX-T, VMware vRealize Suite and VMware Tanzu (for working with containers) into a single software stack with a common monitoring system for providing cloud infrastructure.
The previous two tests showed testing of the disk and computing parts of the cluster separately, but in the real world such selective loads occur extremely rarely in the cluster. Let's move on to the cumulative performance test of relational databases, for which we will evenly distribute 16 virtual machines of the following configuration across the cluster:
- 4 vCPU
- 8 ГБ
- 30 ГБ VMDK (Stripe x6)
- Ubuntu Server 20.04
- MariaDB 10.3.30 (Database with 10М records, total 2.5 GB size)
- Sysbench 1.0.18
To record the results, the arithmetic mean of the indicators of all virtual machines selected by the 99 percentile metric was used.
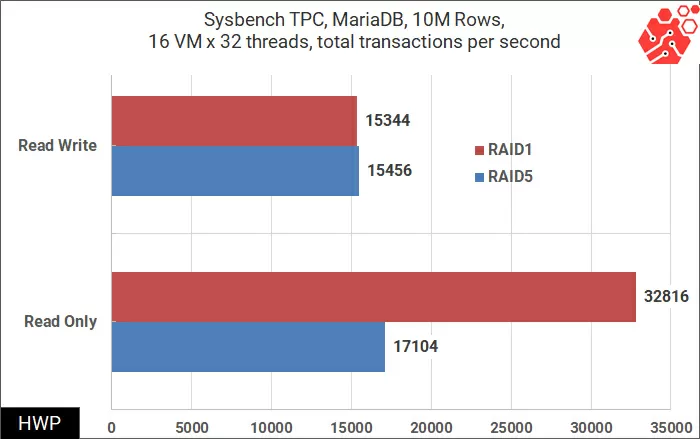
The test results show that a RAID-1 storage policy should be selected for databases with predominant read operations.
Conclusion
The software-defined infrastructure as a whole changes the idea of such key components of the IT part of the enterprise as a storage system or a computing unit. With the transition to the microservices model, the development of container virtualization, IoT systems and hybrid clouds, IT personnel are often required to keep up-to-date the existing infrastructure that was designed for other tasks by the previous generation of engineers. It's hard to believe, but so far such ordinary operations as modernization, decommissioning or disposal of equipment can face interruptions in the operation of services that are tied to the key data flows of the enterprise. It is worth adding to this the desire for carbon neutrality, as it becomes clear that you will not leave on an old steam locomotive in the 21st century.
The hyperconvergent model is one of the simplest on the way to reducing the costs of an enterprise data center. With the apparent total complexity, it is only necessary to enlist the support of the right equipment supplier, and you understand that much in the field of deployment, monitoring and maintenance has already been simplified and accelerated by Lenovo itself, so that the IT service can devote more time to its main tasks. Of course, there is a question of the cost of software, but here we must honestly admit that servicing a homogeneous range of equipment on a single software platform is much cheaper than maintaining work with a "zoo" of devices: storage, SAN switches and servers often from different brands.
Of course, the disadvantages are also present, and they should include relatively high CAPEX: a set of 4 ThinkAgileVX nodes together with licensed software from VMware can be much more expensive than conventional servers + storage, and do not forget that in 1-thread operations, the vSAN cluster behaves "not very". But this is life, and an ideal solution in all respects is fundamentally impossible today, and considering the traditional scheme and the hyperconvergent one, one should take into account not only the question of "hardware" and "software", but also the organizational one: for example, how stable is the market for specialists in installed equipment, is it easy to upgrade/purchase/expand components into the installed infrastructure? What is the vendors ' pricing policy for spare parts and service support packages?
The hyperconverged infrastructure gives a chance to maintain monobrandedness in the data center, and for state-owned companies, when switching to HCI, it is easier to save a supplier for the server fleet when re - purchasing equipment: it is enough to indicate that Lenovo ThinkAgile VX is purchased for compatibility with the already installed Lenovo ThinkAgile VX-and the requirements of the legislation in the field of tender documentation are met.
Michael Degtjarev (aka LIKE OFF)
31/08.2021













{kind=link}
{kind=link}
{kind=link}
{kind=link}