
The evolution of NoSQL, the main advantages over SQL
There is no doubt that the way web applications work with data has changed significantly over the past decade. More and more data is being collected and used, and more and more users are accessing this data at the same time. This means that scalability and performance are more challenging than for schema-based relational databases, which are more difficult to scale.
SQL scalability has been recognized by Internet companies with huge growing data and infrastructure needs, such as Google, Amazon, and Facebook. They came up with their own solutions to the problem – technologies like BigTable, DynamoDB, and Cassandra.
This growing interest has led to a number of NoSQL database management systems (DBMS) with a focus on performance, reliability, and consistency. A number of existing indexing structures have been revised and improved to improve the performance of search and read operations.
First, there were proprietary (closed source) NoSQL database types developed by large companies to meet their specific needs, such as Google's Bigtable, which is considered the first NoSQL system, and Amazon's DynamoDB.
The success of these proprietary systems has led to the development of a number of similar open source database systems and proprietary systems, the most popular of which are Hypertable, Cassandra, MongoDB, DynamoDB, HBase, and Redis.
What makes NoSQL different?
One of the key differences between NoSQL databases and traditional relational databases is the fact that NoSQL is a form of unstructured storage.
This means that NoSQL databases do not have a fixed table structure, as in relational databases.
Advantages Of NoSQL
NoSQL databases have many advantages over traditional relational databases. One of the main differences is that NoSQL databases have a simple and flexible structure. They don't use schemas. Unlike relational databases, NoSQL databases are based on key-value pairs.
Some types of NoSQL database storage include storing columns, documents, key values, graphs, objects, XML objects, and other data storage methods. Usually, each value in the database is indicated by a key. Some NoSQL database stores also allow developers to store serialized objects in the database, rather than just simple string values. Open source NoSQL databases do not require the purchase of an expensive license and can run on inexpensive hardware, making their deployment cost-effective.
In addition, when working with NoSQL databases, regardless of whether they are open or proprietary, scaling is easier and cheaper than when working with relational databases. This is because the expansion is horizontal and the load is distributed to all nodes, rather than the type of vertical scaling that is typical for relational databases, where performance increases are achieved by upgrading the host to a more powerful one.
Disadvantages of NoSQL databases
Of course, NoSQL databases aren't perfect, and they can't always be used as storage systems.
First, most NoSQL databases are not designed to be as reliable as traditional databases. Characteristics such as atomicity, consistency, isolation, and data persistence in NoSQL systems are sacrificed for performance and scalability.
To support reliability and consistency features, developers need to implement their own proprietary code, which makes the system more complex. This limits the use of NoSQL in areas where security and transaction reliability are important, such as banking systems.
NoSQL databases are also not compatible with SQL queries. This means that you need to manually rewrite queries to work with this type of database.
NoSQL vs. relational databases
Let's compare NoSQL with a regular database:
|
|
NoSQL Database |
Relational database |
|
Performance
|
High |
Low |
|
Reliability |
Low
|
Good |
| Availability |
Good |
Good |
|
Data consistency |
Bad
|
Good |
|
Data Size
|
Big to enoromous
|
Medium to large |
|
Scalability |
Easy, unexpensive
|
Easy, expensive
|
Note that the table shows a comparison at the database level, rather than different database management systems that implement both models.
Types of data storage. The Key Value Storage
The key value store type uses a hash table where a unique key points to an element.
Keys can be organized into logical groups that require keys to be unique within their own group. This allows you to use the same keys in different logical groups. All you need to work with items stored in the database is a key. Data is stored as a string, JSON, or large binary object.
One of the biggest drawbacks of this form of database is the lack of consistency at the database level. The most well-known NoSQL database based on the key value store is Amazon DynamoDB.
Types of data storage. document repository
Document stores are similar to key value stores because they do not have a schema and are based on a key-value model. Thus, both have many advantages and disadvantages in common, but there are important differences between them.
In document stores, values (documents) provide encoding for stored data. These encodings can be XML, JSON, or BSON (binary JSON encoding).
You can also run queries based on data. The most popular database application that uses document storage is MongoDB.
Types of data storage. Column Storage
In a column storage database, data is stored in columns, not rows, as is done in most relational database management systems.
A column store consists of one or more column families that logically group specific columns in the database. The key is used to identify and point to a number of columns in the database with a key space attribute that defines the scope of this key. Each column contains tuples of the names and the values are ordered and separated by commas.
Column stores have high read and write speeds. Here, all rows corresponding to a single column are stored as a single record on disk. This is done for faster access during read / write operations. The most popular databases that use column storage include Google BigTable, HBase, and Cassandra.
Types of data storage. Graph databases
Formally, a graph is representation of set objects where some pairs of objects are connected by links. Interconnected objects are represented by mathematical abstractions called vertices, and the connections that connect some pairs of vertices are called edges. The set of vertices and edges connecting them is called a graph.
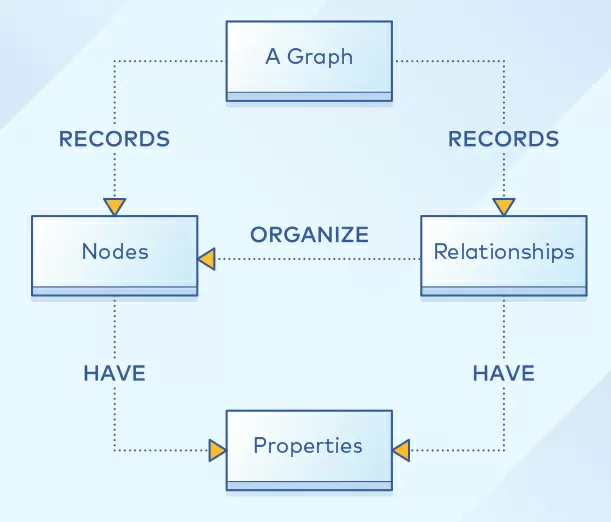
Currently, InfoGrid and InfiniteGraph are the most popular graph databases.
NoSQL Database Management Systems
For a brief database comparison, the following table provides a brief comparison of various NoSQL database management systems.
|
Database |
Storage type |
Query language |
Interface
|
Programming language | Source code |
|
Cassandra |
Columns
|
Thrift API |
Thrift | Java | Open |
|
MongoDB |
Docs |
Mongo Query |
TCP/IP | C++ |
Open
|
|
HyperTable |
Columns |
HQL |
Thrift | Java |
Open
|
|
CouchDB |
Documents |
MapReduce |
REST | Erlang | Open |
|
BigTable |
Columns |
MapReduce |
TCP/IP | C++ | Open |
|
HBase |
Columns |
MapReduce |
REST | Java | Open |
MongoDB has a flexible storage scheme, which means that stored objects do not have to have the same structure or fields. MongoDB also has some optimization features, due to the distribution of data sets.
Cassandra
Cassandra is a database management system developed by Facebook to store huge amounts of data distributed between different nodes. Cassandra's goal was to create a DBMS that does not have a single point of failure and provides maximum availability.
Cassandra is basically a column storage database. In some studies, Cassandra is referred to as a hybrid system that has a lot in common with Google's Bigtable and Amazon's DynamoDB.
Особенности Cassandra:
When a failure occurs in one of the Cassandra nodes, data on that node will be unavailable, but other nodes (and data) will still work.
Distributed hashing is a scheme that provides hash table functionality in such a way that adding or removing a single slot does not significantly change the mapping of keys to slots. This makes it possible to distribute the load between servers or nodes according to their capacity and, in turn, minimize downtime.
The client interface is relatively easy to use. Cassandra uses Apache Thrift, a cross-language RPC client, but most developers prefer open source alternatives built on top of Apple Thrift, such as Hector.
One of the features of Cassandra is data replication. In fact, it reflects data to other nodes in the cluster. Replication can be random or specific to maximize data protection by hosting the node in a different data center. Another feature of Cassandra is the partitioning policy, which determines where and on which node to place the key. The location can be random or ordered. When using both types of partitioning policies, Cassandra manages to find a compromise between load balancing and query performance optimization.
Consistency. All nodes must be up-to-date at any given time with the latest values. This is a complex, configurable process, so Cassandra maintains a balance between replication and read/write operations, allowing the developer to customize replication to suit their needs.
Reading/Record. The client sends a request to a single Cassandra node. The node stores data in the cluster in accordance with the replication policy. Each node first makes changes to the data in the commit log, and then updates the table structure with the changes, and this happens synchronously. The read operation is performed in the same way: a read request is sent to a single node, and this single node determines which node contains data, according to the partitioning/allocation policy.
MongoDB
MongoDB is a document-oriented database written in C++. The database is based on document storage, which means that it stores values (called documents) as JSON encoded data. This is very important, because even if the data is embedded in JSON documents, it will still be available through queries and indexed. The following sections describe some of the key features available in MongoDB.
As mentioned above, MongoDB uses the RESTful API. To get certain documents from the database, a request document is created that contains the fields that the required documents must match.
MongoDB has a group of servers called routers. Each of them acts as a server for one or more clients. Similarly, a cluster contains a group of servers called configuration servers. Each of them contains a copy of metadata indicating which segment contains which data. Read or write actions are sent from clients to one of the router servers in the cluster and automatically routed by this server to the corresponding data segments using configuration servers.
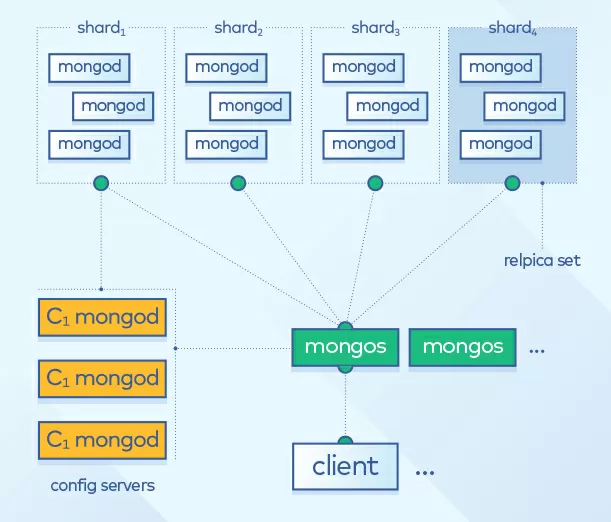
In the image above, we see the MongoDB architecture described above, showing router servers in green, configuration servers in yellow, and segments containing blue MongoDB nodes.
It should be noted that segmentation (or data exchange between segments) in MongoDB is fully automated, which reduces the failure rate and makes MongoDB a highly scalable database management system.
Conclusions
It is important to note that NoSQL is a good addition to existing database standards, but with a few important caveats. Due to the lack of simple consistency mechanisms, NoSQL is still a specialized solution, since the number of applications that can rely on NoSQL databases is limited.
Ron Amadeo
22/02.2019







