
Review of the 4-CPU Lenovo SR860 V2 server based on Intel Xeon Cooper Lake
Today we are testing a very special server from the family of vertically scalable x86 systems. The Lenovo SR860V2 quad-processor is designed to handle mission-critical workloads such as transactional and resident databases, analytics, artificial intelligence, machine learning, big data, and enterprise resource planning tasks. Once upon a time, some of these tasks required supercomputers, but today they can be shifted to a single compact platform with a height of 4U.

If we consider the Lenovo SR860 V2 in numbers, the values are simply amazing:
- up to 12 TB of RAM DDR4 3200 MHz
- four 28-core Intel Xeon Platinum 8380H a total power of 1000 W,
- four network ports with a total speed of 100 Gbit/s,
- four power supply total power 6.4 KW
- up to four RAID controllers, do not occupy a slot GPU
- up to 368 TB SSD storage
- up to 48 drives of 2.5-inch
- up to 4 boards Nvidia V100s
Whatever aspect you consider, there will be several times more of this here than in a standard x86 server. And the price of such a system will be appropriate. The server tested in our configuration had a cost of about $ 637,000 (and with a starter set of SSDs). And although the price will be significantly lower for the customer, taking into account the partner discounts, this is definitely the most expensive device that we have tested in the last 23 years of our work.
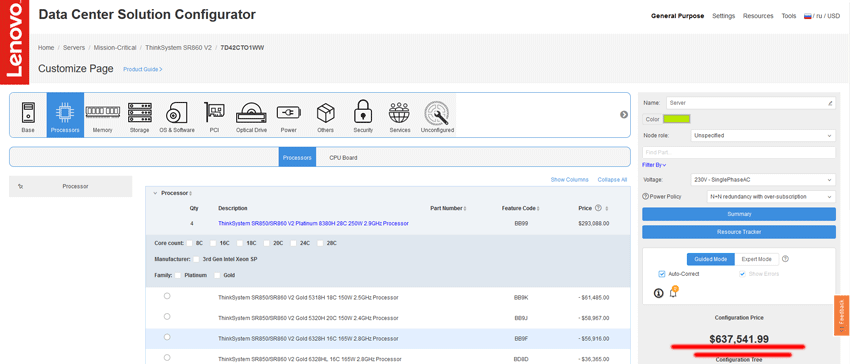
Given that the customers of such servers know what they are buying and why, for them, the developers do not save on components and modern technologies.
Interior
Of course, it would be strange to expect some design errors from a machine worth under a million dollars, and if anyone thought that the transition of the" server legacy "of IBM to Lenovo would reduce the quality of detail processing - I hasten to please: structurally, this is a small masterpiece (if "small" can be applied to a 4U machine weighing 30 Kg), adequately continuing the school of server construction, laid down in the days of IBM. You will need a screwdriver only once to open the lock of the upper cover of the case, and then you will be surprised that this whole machine is assembled without a single screw, on latches and brackets, it is reassembled with your bare hands, and the customization possibilities are best indicated by the fact that even the USB ports on the front panel can be replaced with other ones: as they say, any whim for your money!

Usually you imagine that in a 4-processor server, all the CPUs are installed in a row on one motherboard, but here everything is different: two processors are located on the main motherboard, and two more are located on the additional board, which is installed above the first two CPUs. Yes, a 4-unit case rarely uses vertical space so effectively: it is usually empty, but here the developers were faced with the task of placing 48 memory slots - and they did it in such an elegant way. Just look at the final layout of the case: here you can install expansion cards of any length, because they do not rest on the processors, but are located above them. Of course, this arrangement is very inconvenient when something breaks down, and for example, to get access to the memory slot on the lower processors, or to the lower PCI Express cards, you need to disassemble the entire server: pull out the two SSDs from the back of the case, remove all the expansion cards, pull out the RAID adapter supercapacitor (if available), disconnect the SATA cable of the frame with the riser, remove the upper frame with the riser, unfasten the cables from the tray with the processors (more on them below), remove the tray itself - and then you will have access to the desired device. After that, collect everything in the reverse order. In fairness, it should be said that in such machines as the SR860 V2, "unplanned downtime" happens less often than in conventional 1 - and 2-socket servers: built-in monitoring systems with predictive analysis (about them a little later) warn in advance of a possible failure of the component, and in real combat conditions, the operation of the equipment is duplicated, so that instead of” unscheduled replacement " all operations are carried out in a quiet mode, at the scheduled time, without stopping workflows.
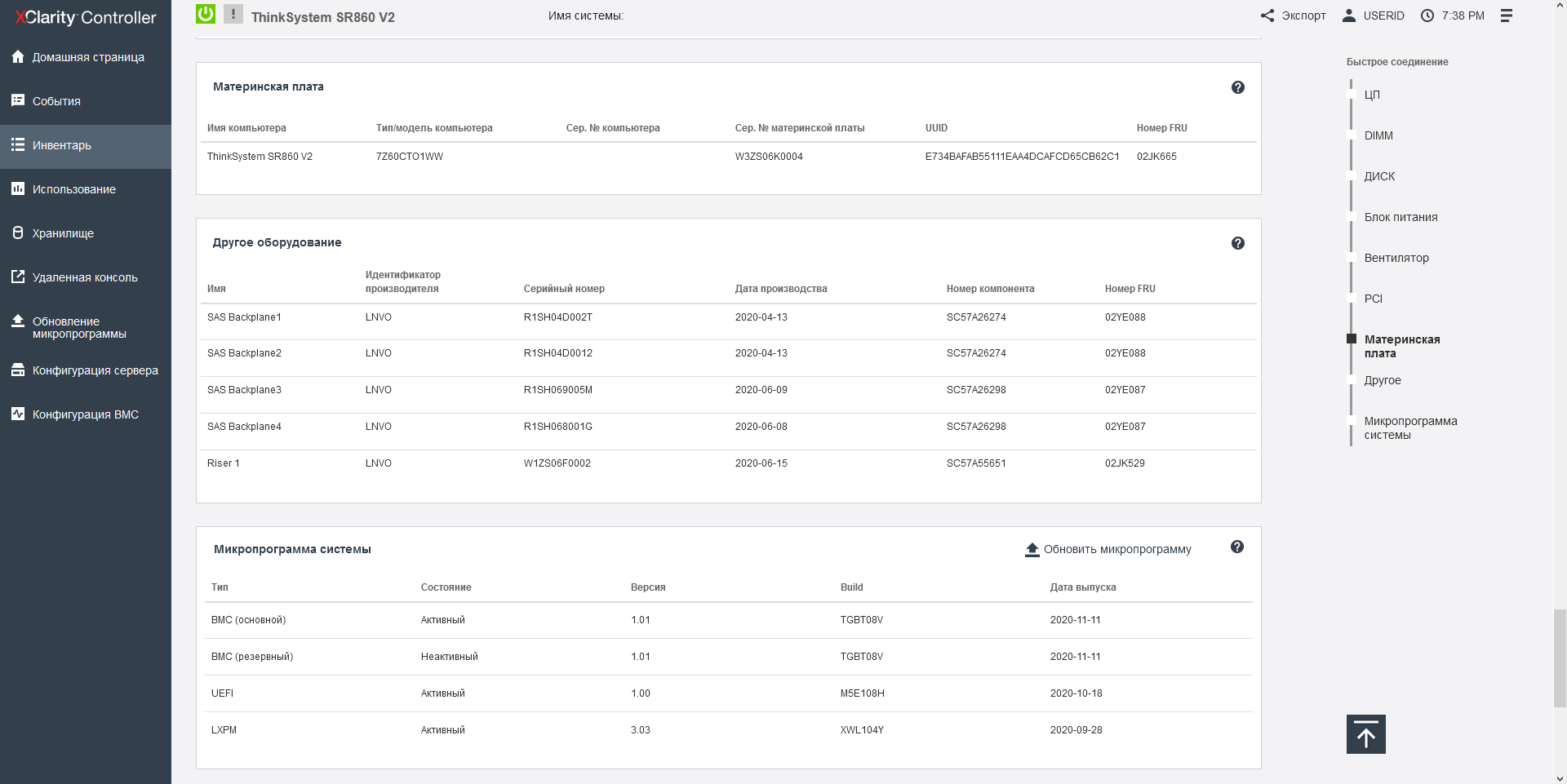
Interestingly, the contact groups of the UPI bus between the two parts of the motherboard are simply huge, designed specifically for this design, and are not found anywhere else. To reduce the number of split pins, the NVMe buses are routed from the processors to the disk buckets with thick SAS-like cables.
Cooling system
With such a unique arrangement of processors, somehow the radiators look too primitive, and after all, each Intel Xeon 8380H consumes up to 250 watts. The radiators have a height of 1U, which would seem strange in any other, but not this server: here 4 CPUs already occupy half the height of the cabinet space, and above them is a compartment for expansion cards. Of course, to remove heat in such a dense structure, a powerful air flow is required.
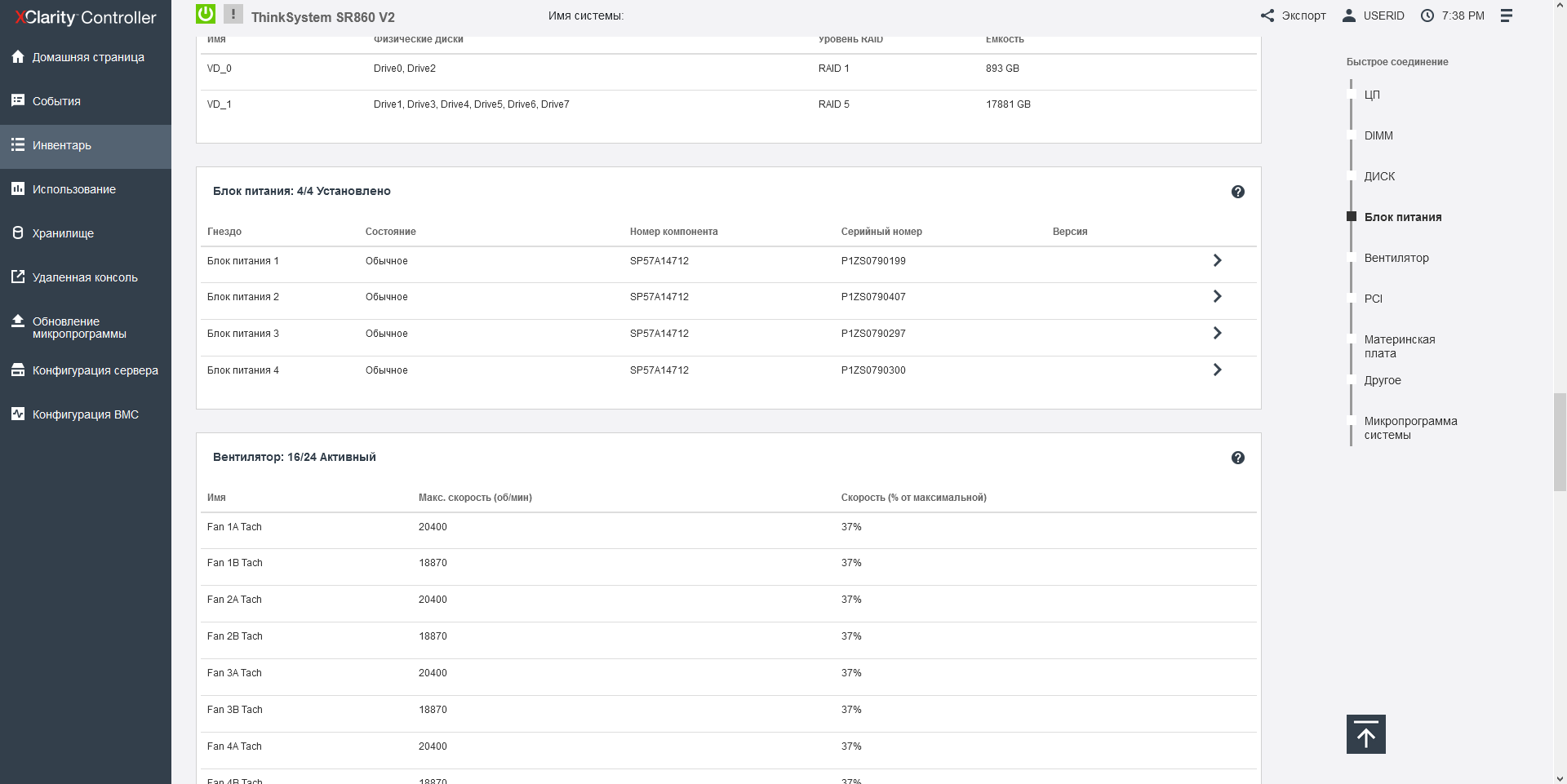
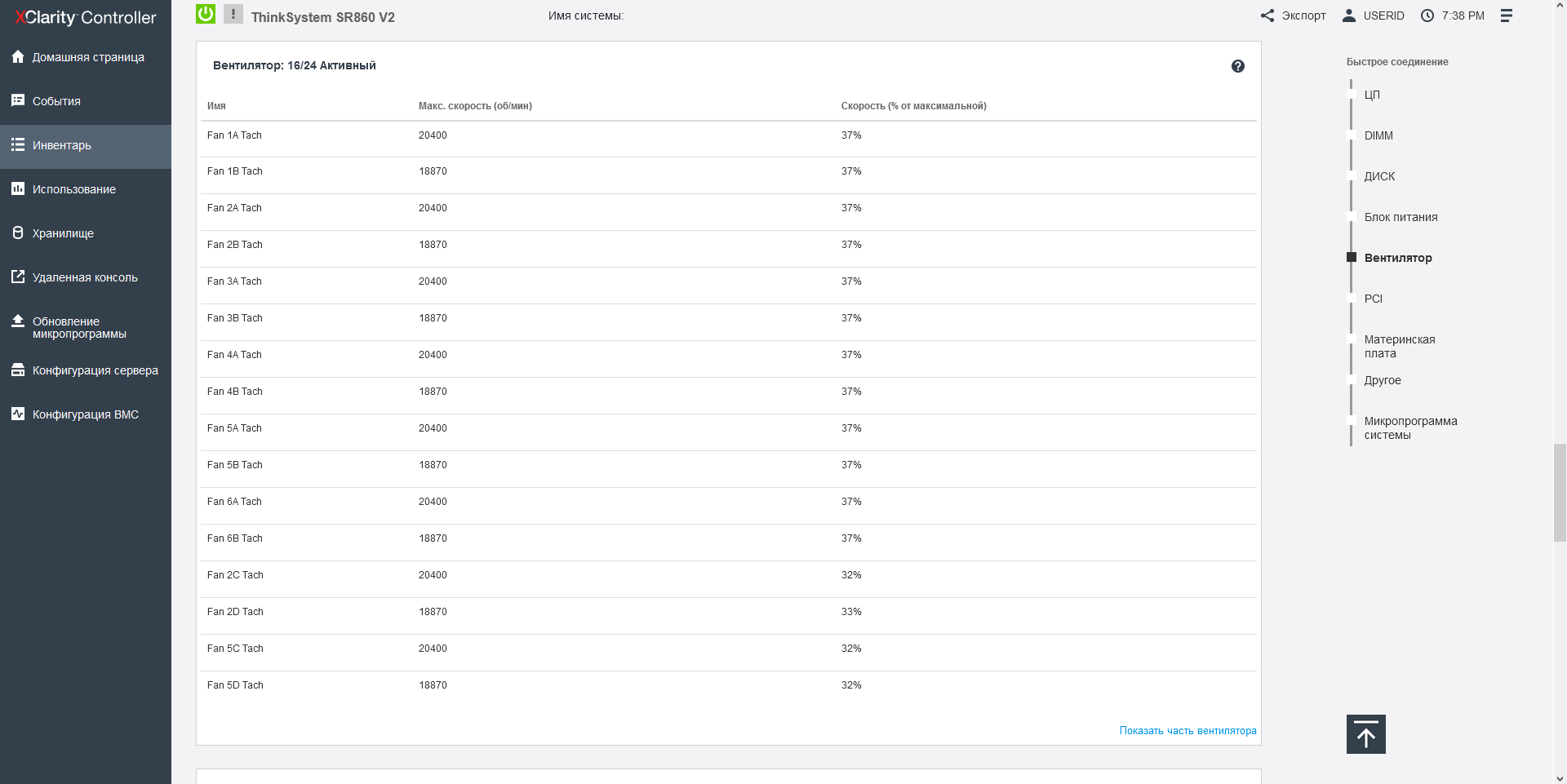
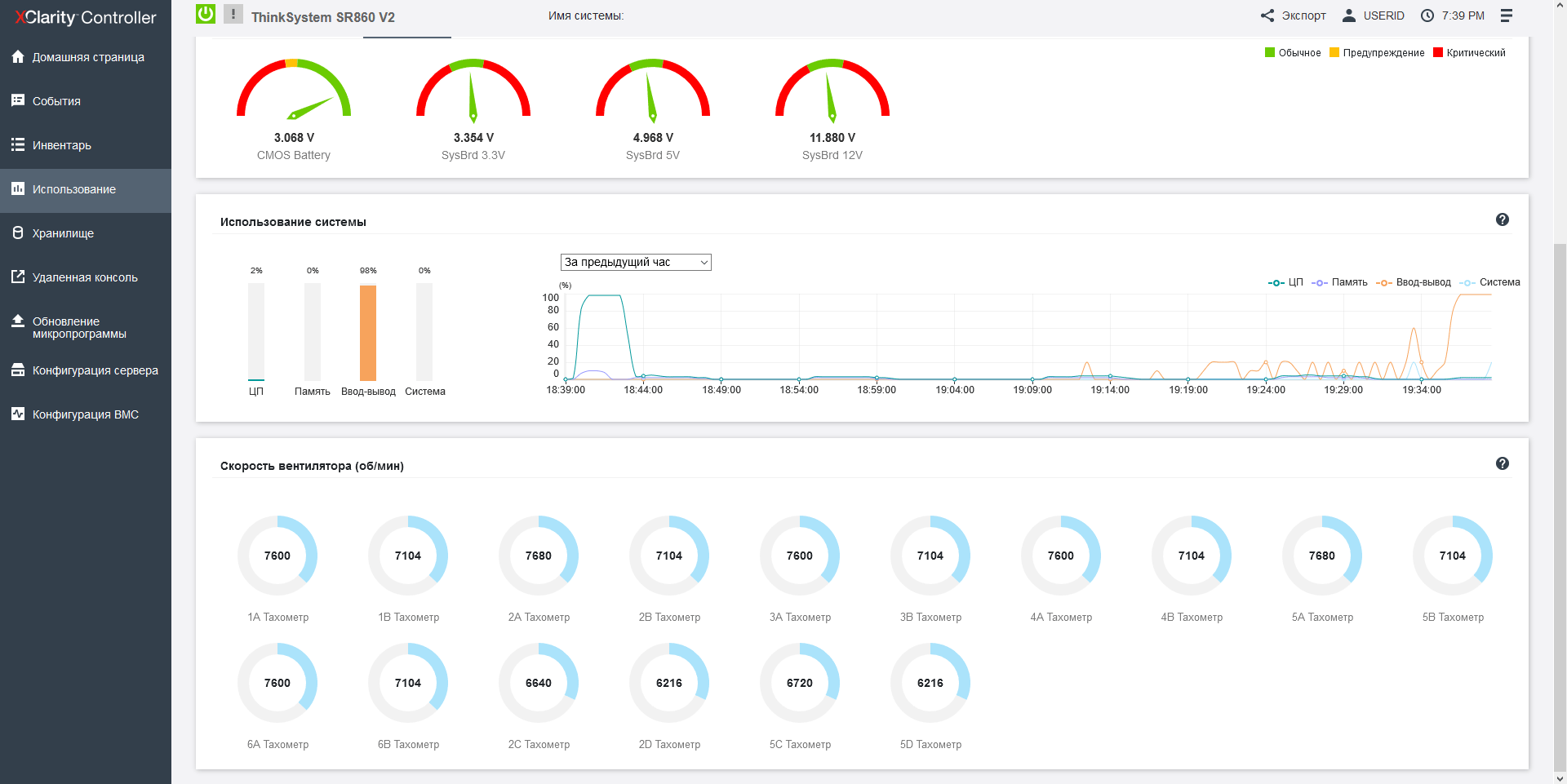
For cooling Lenovo ThinkSystem SR860 V2 is responsible for a block of 8 dual 60-mm fans, located in 2 levels, and not symmetrically. There are only 2 fans on the upper level, and 6 on the lower level. The fans have a hot-swappable function, and the unit with them can be easily removed "cold". For 2-processor configurations, the cooling system is represented by single fans with lower power. The arrangement and design of the fans themselves look strange to me: I have no doubt that the developers modeled the air flow using formulas and effects unknown to science, because how else could they have placed a through hole instead of a third fan on the upper level? And after all, it worked - the processor opposite this hole is always colder than the rest in the server.
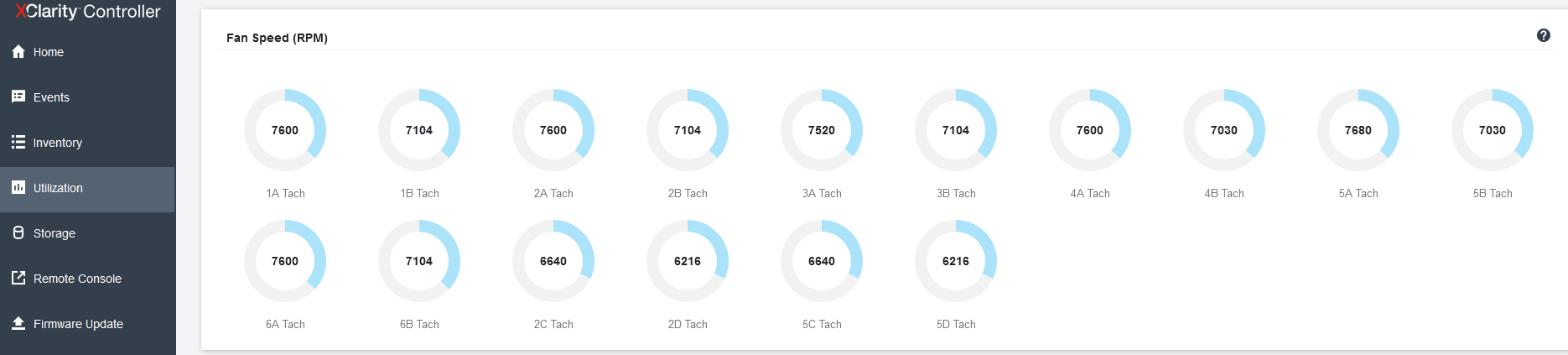
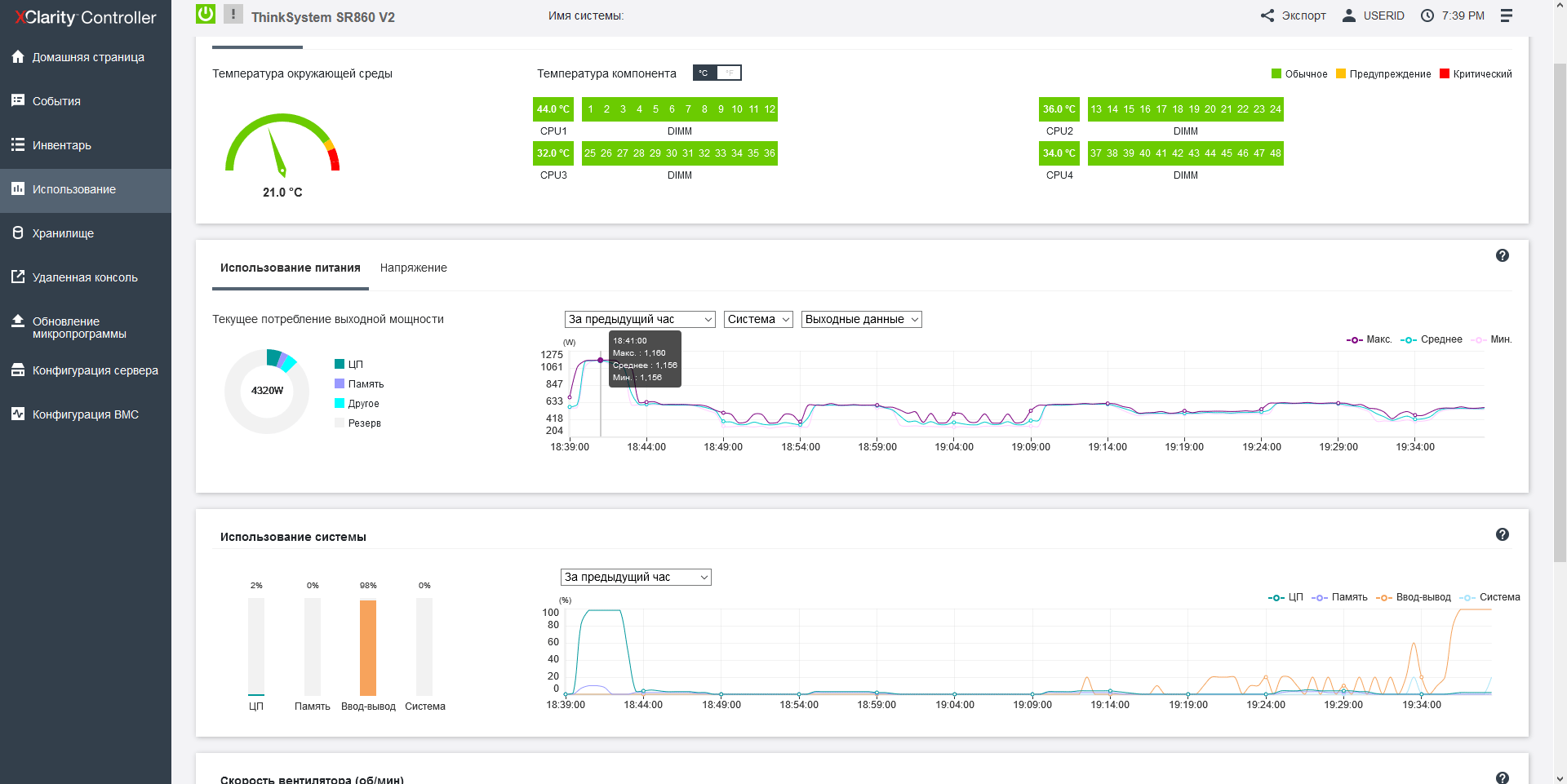
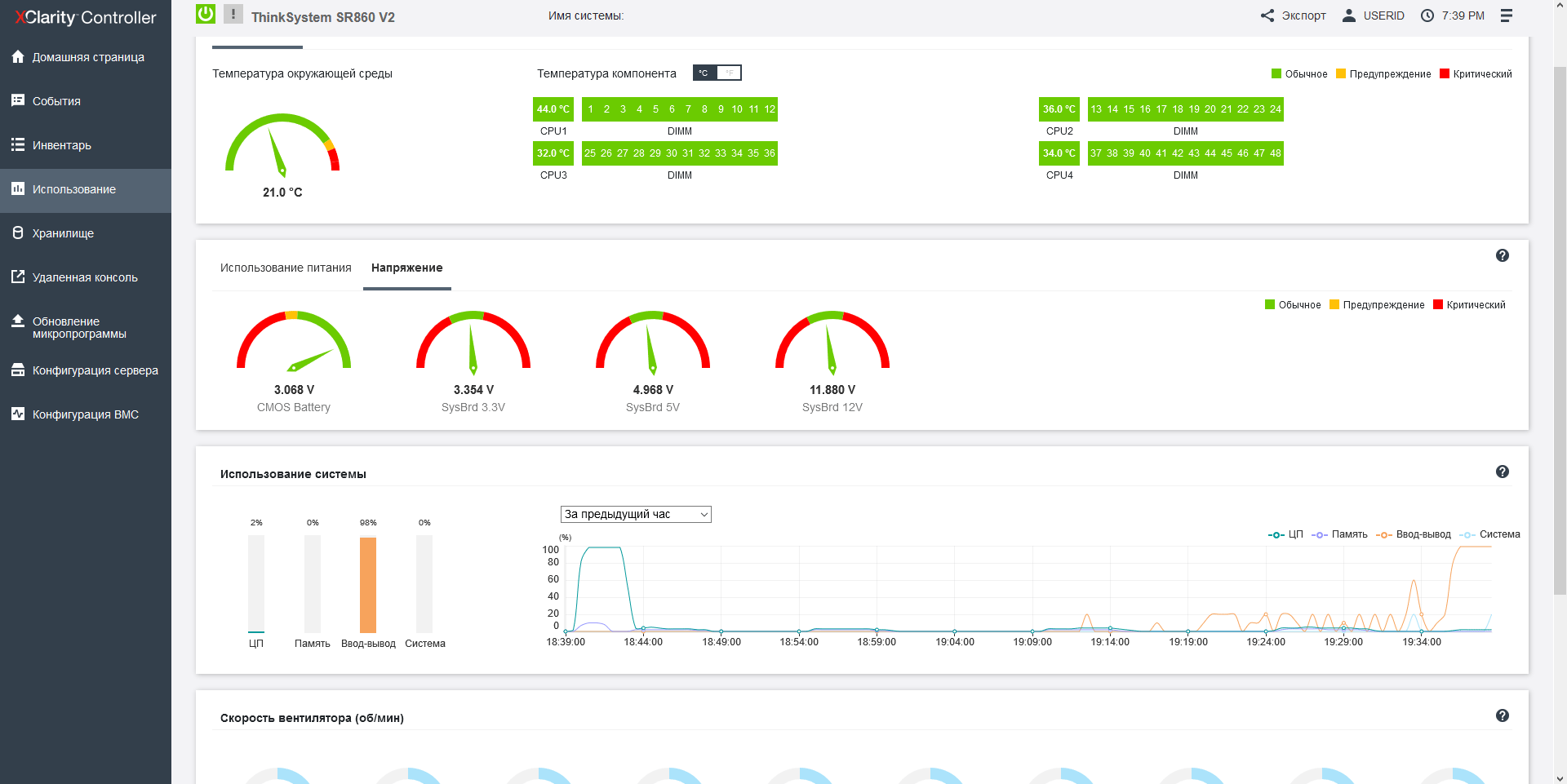
Each fan is independently monitored and controlled by the server controller. In our article about "Epic Hosting", we noticed that the buyer of the most heat-loaded configurations is not immune from overheating, especially on the top-end processors, which include the Intel Xeon 8380H installed here. The fact is that the maximum CPU load is not so easy to ensure: most applications to some extent rest on the network, the data storage subsystem or the features of the program code and give the processors time to rest, so even running synthetic Burn - In tests OCCT or the well-known Cinebench R23, it is not possible to load the 112 cores available here at full capacity - in these tests, the CPU temperature hardly exceeds 56 degrees Celsius. It is quite another matter - large-scale calculations that actively use both the memory bus, and computing blocks, and the inter-socket bus. In our case, such a load is provided only by financial software, namely, the simulation of trading robots in the MetaTrader 5 program, which we can now use to check the machine for overheating, observing the temperature regime in the convenient power consumption section of the Lenovo XClarity Controller.
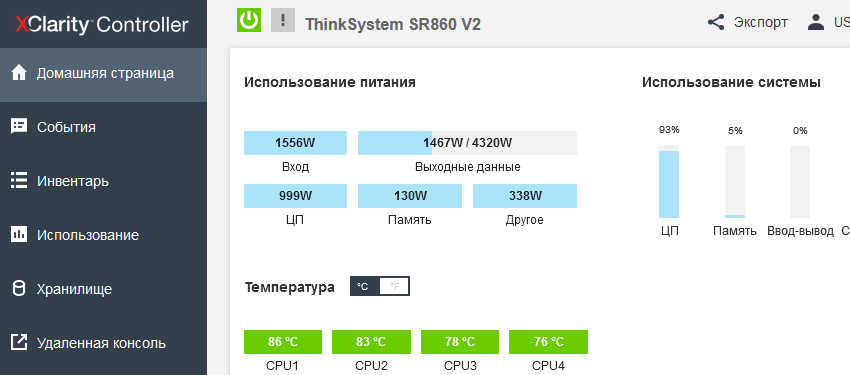
Once again, I note that in all tests, the temperature of the 4th processor is significantly lower than the rest due to the hole in the panel with fans, but in general, at an ambient temperature of 25-26 degrees, it is possible to do without trottling the processors, and it is not possible to overheat the machine.
Computing subsystem
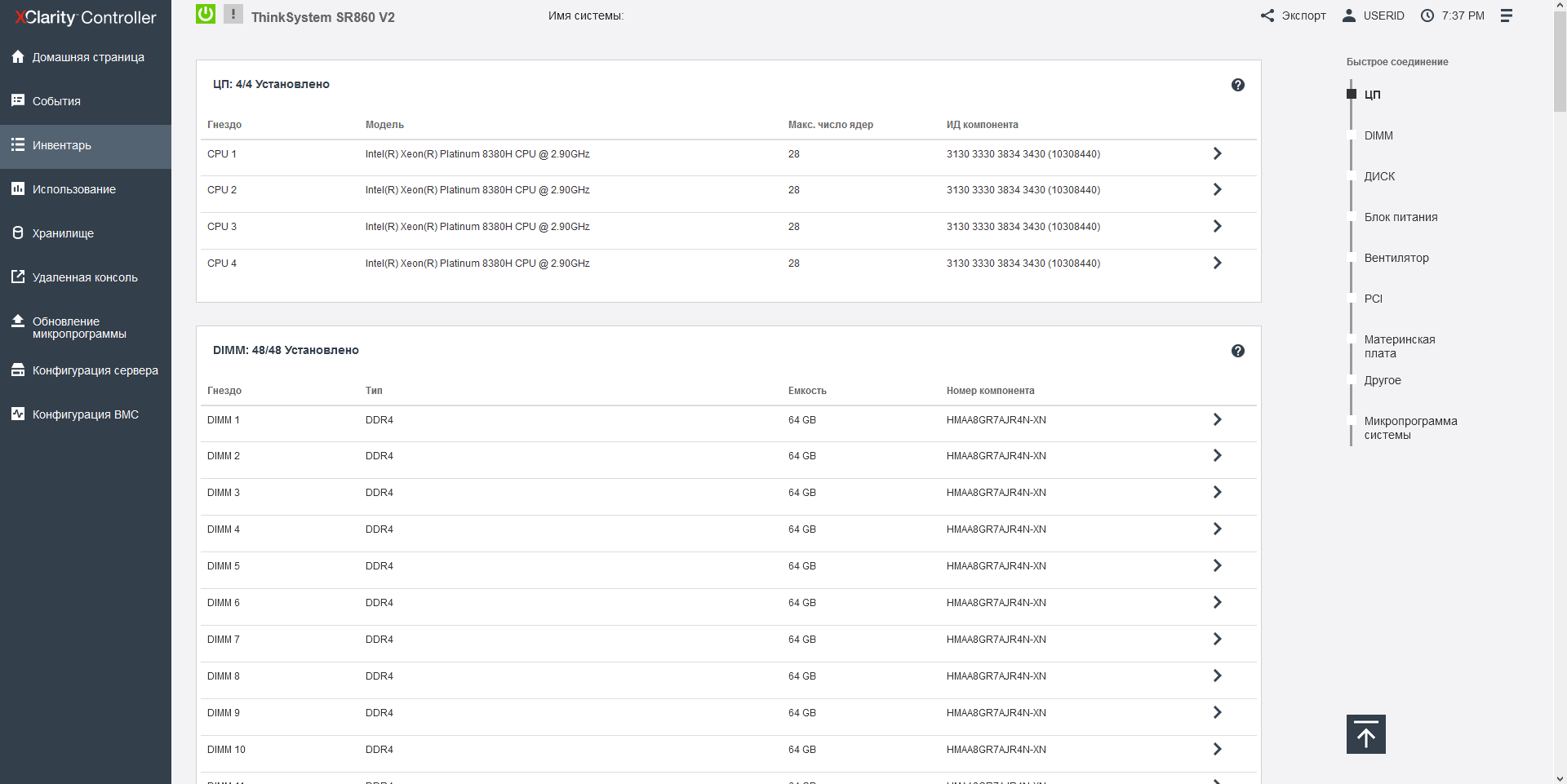
The most interesting thing about the server in question is, of course, 4 high-performance Intel Xeon Platinum 8380H processors with the Cooper Lake architecture. Each of the processors has 28 cores plus supports Hyper-Threading, which gives a total of 224 threads. The nominal frequency of 1 core is 2.9 GHz, and the maximum is 4.3 GHz, the cache is 38.5 MB, and the maximum power is 250 watts.
In the last 2 years, Intel has faced certain difficulties and challenges of our time. First, these are " shadows of the past” in the form of vulnerabilities of the MeltDown / Spectre family, the correction of which led to a slowdown in some operations. Secondly, it is the constantly increasing power consumption of processors, which increases the cost of the cooling and power subsystem of top-end server models. And here, of course, the new Cooper Lake architecture can be considered a small victory: these processors are invulnerable to Meltdown attacks & Spectre is on the hardware level, so if you used to disable protection in favor of higher performance - now you don't need to worry about it. If we talk about energy saving, then of course Intel went out of its way to reduce the heat package as much as possible, being limited to the 14nm process technology. Of course, the maximum frequency is stated at 4.3 GHz, but with the caveat that it depends on the degree of load of the cores. To find out exactly how the frequency is adjusted, let's take a test program CPU-Z, which unevenly distributes the stress load flows, first fully loading only one processor, and only then moving on to the next. This is exactly what we need to understand the Xeon Platinum 8380H frequency matrix.
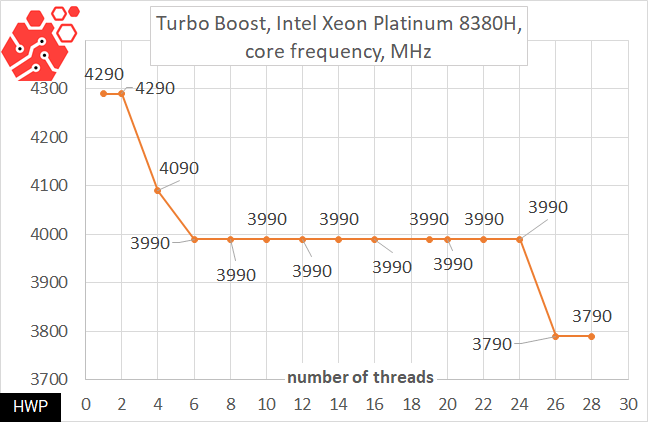
Figuratively speaking, if your operating system distributes threads well between sockets, then in Lenovo SR860 V2 you can see how 8 threads will work on cores with a frequency of 4.3 GHz, if they went to 4 processors, well, if one, then-almost 4 GHz, which in general, is also not bad. But usually, in problems where the Affinity parameter is not set directly, it is impossible to predict the distribution of flows, and you need to count on something average, about 4 GHz.
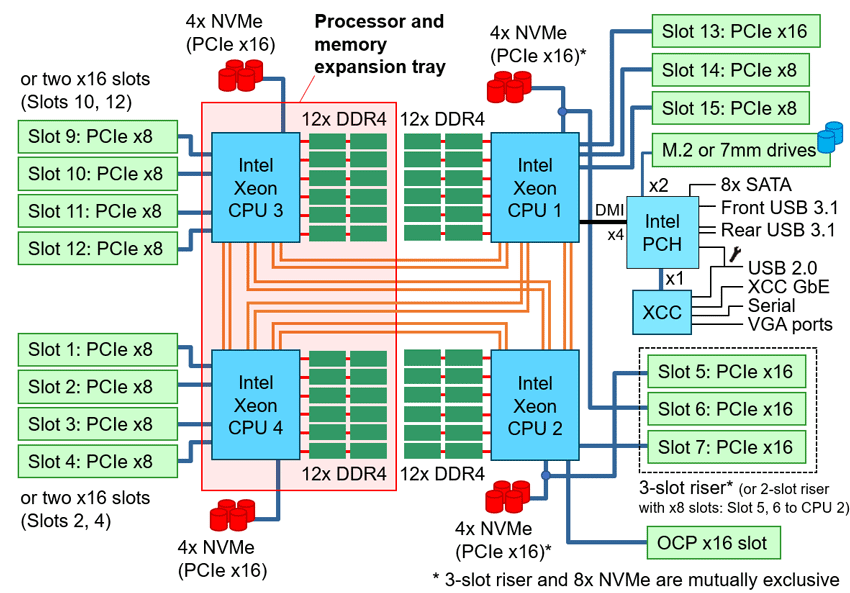
The 4-processor configuration uses a 6-channel UPI topology, so that each of the processors is connected directly to any other by two interprocessor channels with a maximum throughput of 10.4 GT/s. The fast inter-socket bus allows the Cooper Lake architecture to efficiently perform highly parallel tasks, such as implementing artificial intelligence output algorithms.
 |
How and why we compared? To be honest, we do not have a server available that we could oppose the 4-head monster from Lenovo. I asked our partners who had powerful servers available for comparison, including a 2-processor machine on the EPYC 7742, but no one dared to participate in the comparison. We have a first-generation AMD EPYC 7751p available, which I still decided to add to some tests not for comparison, but for understanding the scale, so that you can draw conclusions based on something: it is a lot or a little.
OS:
|
Intel has long advocated the use of the TensorFlow and PyTorch frameworks on the CPU, at least in tasks where a ready-made AI model needs to be applied in practice, but there is no access to the GPU. For this purpose, Intel has created its OpenVINO development environment, which aims to implement Python applications with neural networks on the CPU. Let's test one of the tasks - "checking accuracy" on the basis of the Resnet 50 dataset.
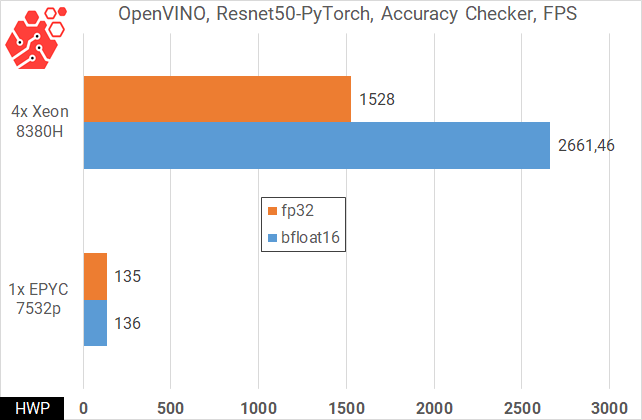
Specifically, in the case of Resnet50, the test results demonstrate that Intel can easily beat off some tasks from Nvidia and take them to the CPU. Of course, the reader will be right that from an economic point of view, running Pytorch and Tensorflow on the CPU is impractical, and you can argue on this score endlessly. It is quite another matter when the framework does not use Python, but is implemented only on the x86 architecture.
Let me make a small lyrical digression and talk about trading: perhaps, each of us received offers to buy a robot for trading on the Forex, stock or cryptocurrency market. The financial sector, where trading robots operate according to a predetermined algorithm, is called "algo trading", and traces its history back to the 80s of the last century. By the way, algo trading is the pinnacle of evolution in the financial and computer world, and this world in its development is decades ahead of the rest of the industry. By the way, now from every iron there are songs of praise for neural networks and machine learning, so-algotrading survived this wave somewhere in 2008-2010, and now there are quantum algorithms in use with constant additional training. In fact, it looks like this: posts from social networks, videos from YouTube and CNN, comments from forums and data from the quotes of all trading pairs for the entire history of trading flock to the computing cluster. In real time, the machine optimizes the parameters taking into account the probabilities of market movement, crowd sentiment, money volume and other values, which can be hundreds, and forms its trading strategy. And, as a rule, such calculations are performed on high-performance computing nodes with high-speed interfaces and a huge amount of memory, and even on quantum computers, because successful traders are not constrained in funds, and can afford any equipment.
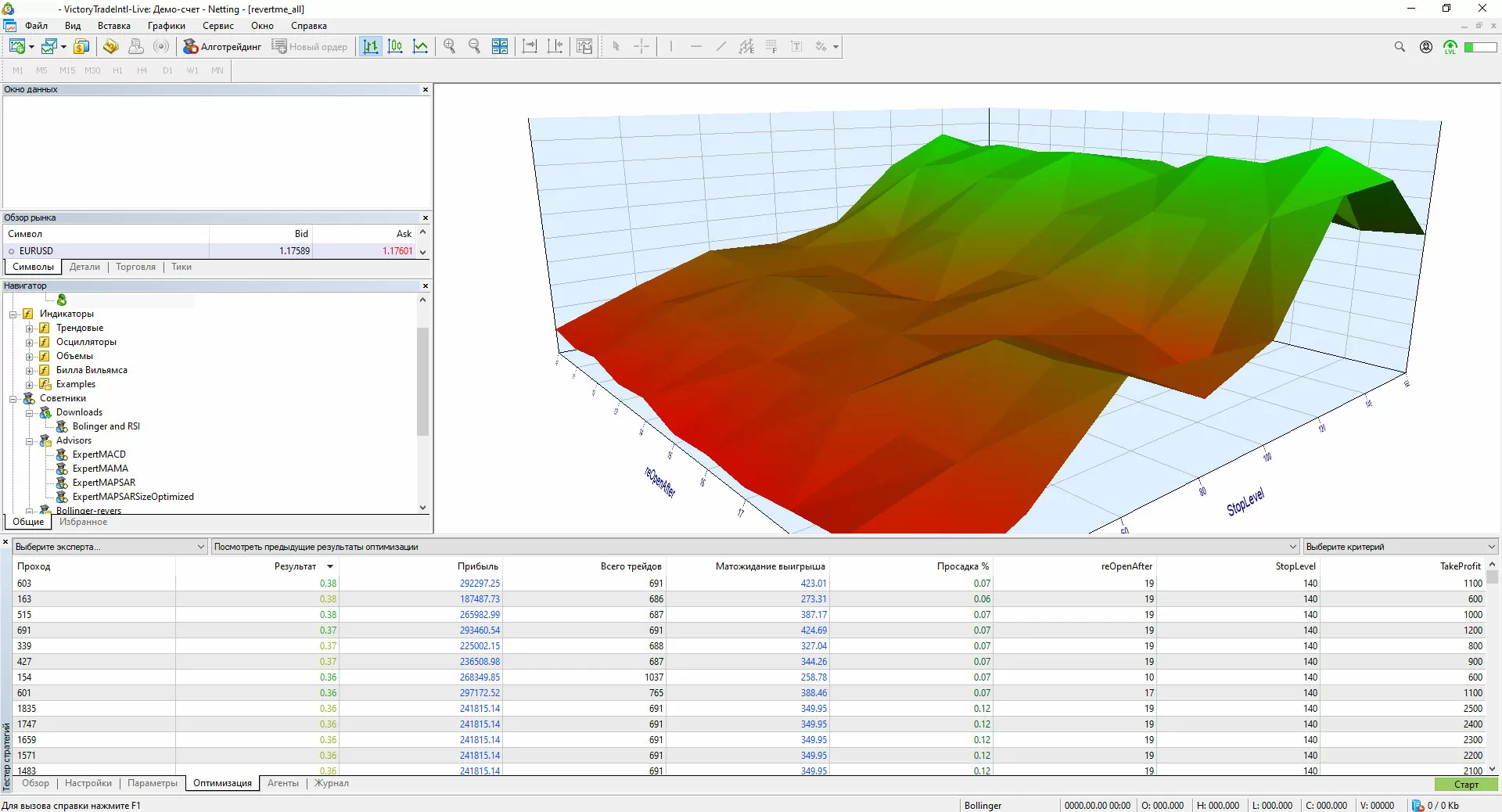
Fortunately, you don't have to have millions of dollars in your accounts to touch the world of algo trading. The free trading platform MetaTrader 5, developed by our compatriots, has now become the de facto standard for algorithmic trading and is supported by all Forex platforms without exception. And let it look like an advertisement, but the adherents of algo trading have learned to attach third-party libraries to the MetaTrader 5 trading robots, including using neural networks. I am particularly pleased to see how in the process of training robots, MetaTrader 5 squeezes all the juice out of the server, and where previously it took days and weeks for calculations, today it takes hours. I performed optimization based on the Bollinger strategy and the RSI indicator, using the data of the 15-minute timeframe for the last 10 years as Big Data. A search of 9842 parameters with the "maximum profitability"evaluation criterion was implemented.
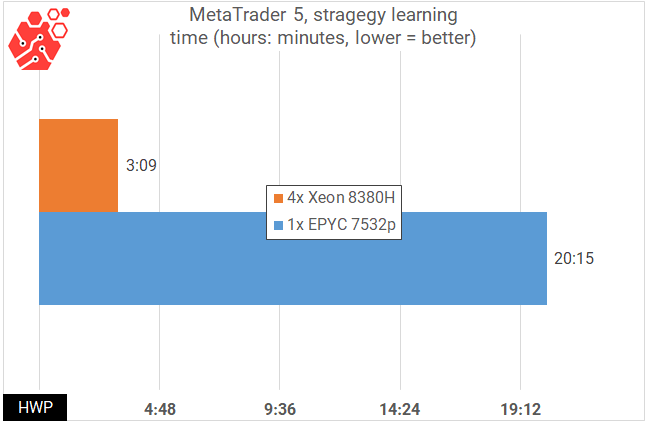
This means that the existing model can be retrained, optimized and restarted during the trading session - this is what Lenovo means when it says that the 4-processor SR860V2 server is designed for trading. This is not HFT applications that are now going to FPGA - here even our simple test for the EUR/USD trading pair using the trading history for the last 10 years, used 120 GB of RAM, and the more complex the trading algorithm, the higher the load on the machine will be, and it will simply not be possible to solve this problem in the cloud due to the high load on RAM.
In general, if you look at the frequency capacity of the server, equal to 319 GHz, you understand that any Cloud provider would not hesitate to sell their soul for such a powerful host (read about why cloud hosters use the general frequency of the server in our article about "Epyc Hosting"), but vertically scalable systems in their business are not in demand because of the exorbitantly high price: two 2-processor servers will cost much cheaper than one 4-processor. However, when choosing a virtualization system, note that both the Cooper Lake architecture, disk controllers, and the network stack in the Lenovo machine require the latest operating systems: for Windows, this is Server 2019, for Linux, the kernel from 5. x and higher, and for VMware, ESXi 7.0.1, and for older operating systems, there are no drivers. It is worth noting that recently this has become a common practice for both hardware and software vendors of corporate systems: the latest hardware requires the installation of the latest software versions.
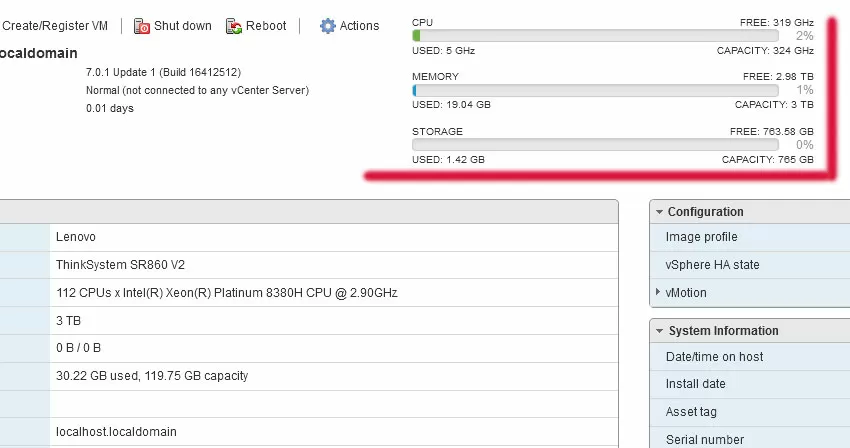
If you are limited to using old operating systems (for example, due to the presence of certificates), then the new hypervisor saves you: even Windows Server 2008, 2016 and Windows 10 work normally under ESXi 7.01.
I know that readers will not forgive me if I do not test the" desktop " package Cinebench R23, so that you can compare the Hi-End server with your laptop, and here you have a crazy 73-80 thousand points.
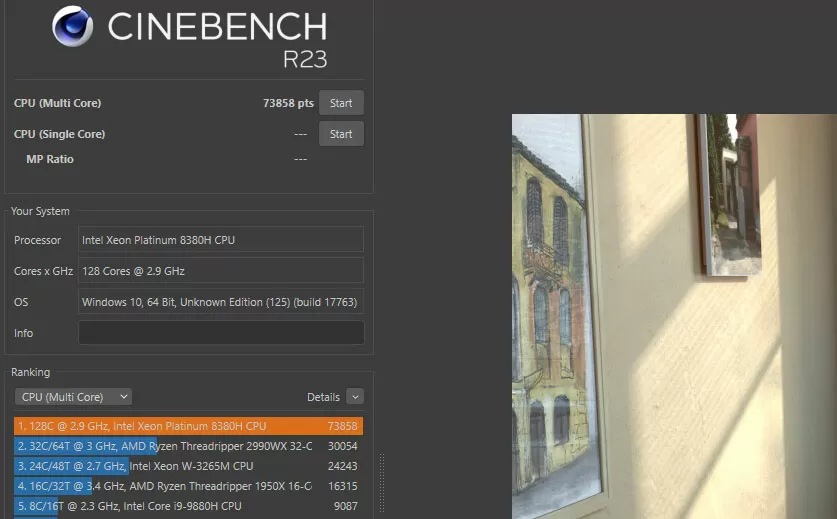
Is it too much? In quantitative terms, these are huge numbers, but in comparative terms-somewhere near the absolute record set at the time of testing by a single desktop processor AMD Threadripper 3990. In general, the task of rendering is well-traveled, and even if you look at the power consumption of the machine, it does not reveal all the potential inherent in the server, but the software for modeling is quite.
Memory subsystem
Each of the 4 Intel Xeon 8380H processors has a 6-channel DDR4-3200 MHz memory controller, so we can say that the machine communicates with the memory subsystem via 24 channels, and here AMD has nothing to cover: even the latest EPYC 7xx3 on the Milan core can have a maximum of 16 memory channels in 2-processor machines.
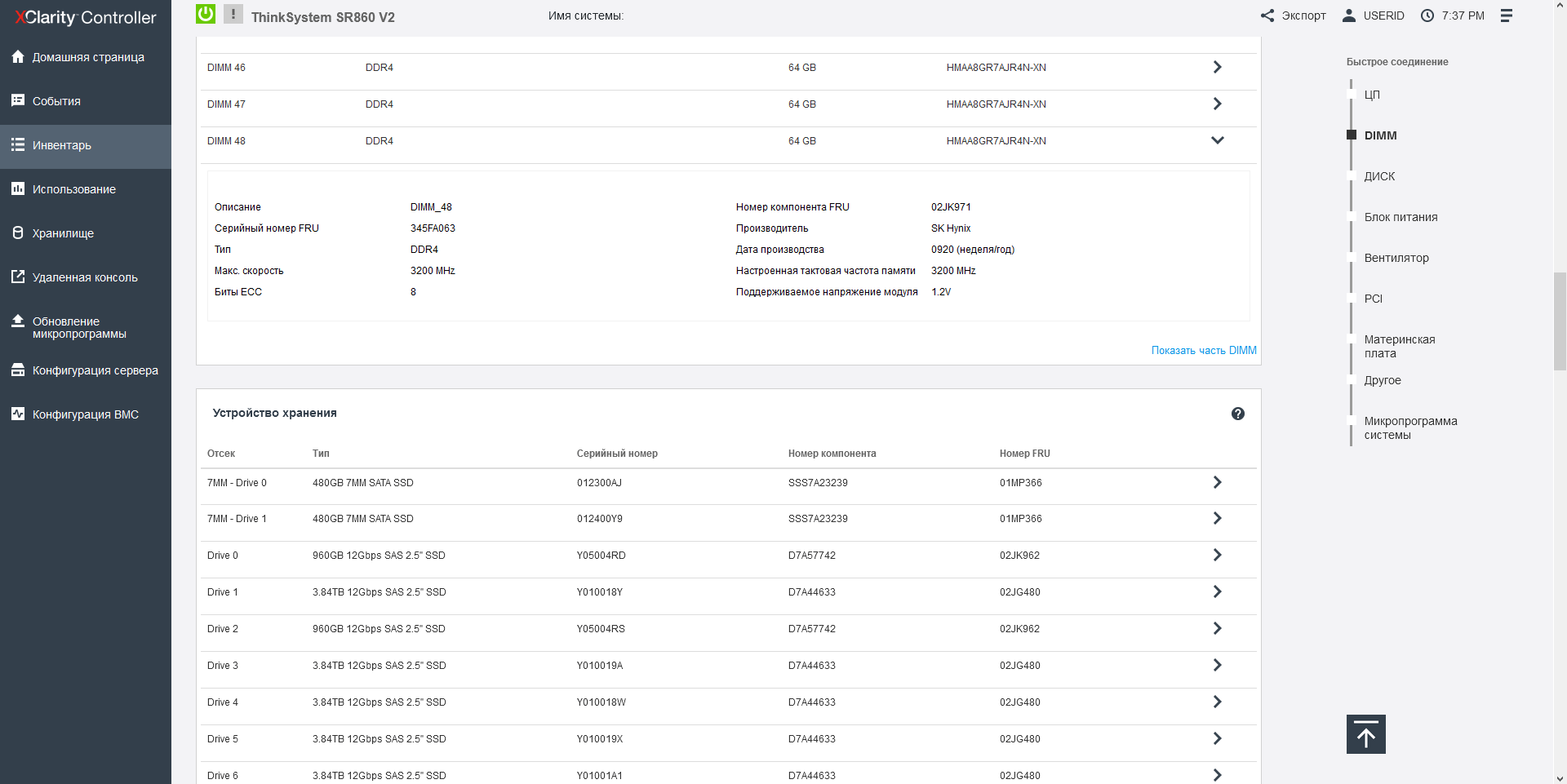
Note that Intel Xeon processors with an H index, such as our test 8380H, allow you to install up to 1.125 TB of RAM on the CPU, and models with an HL index - up to 4.5 TB. In all the documentation for the server, Lenovo calls the memory the word TruDDR4, and I think it should be noted that this is a purely marketing term, meaning that before installing it in the server, the memory was selected, and the best of the best chips were selected, but technically it is just DDR4-3200, without any innovations. The server also supports non-volatile Intel Optane Memory 200 in App Direct mode.
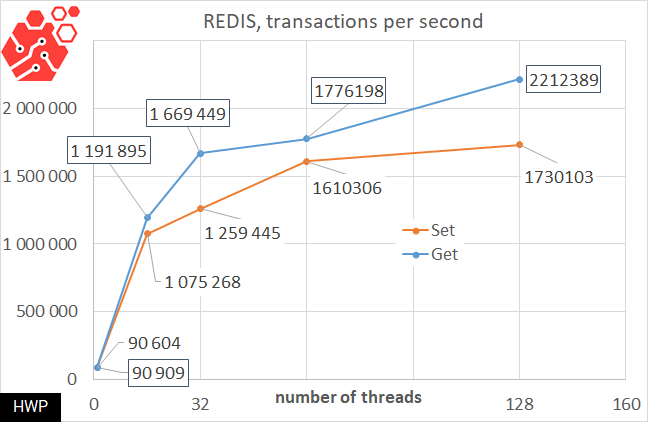
In general, I thought that Redis could not scale above 1.2 million transactions per second, but the 4-processor server managed to dissuade me. I recommend that you turn to our testing of Redis on a server with two top-end AMD EPYC 7742, where we did not even reach 1 million TPS. The thing is that Redis is still in a state of development, and the performance of the database depends very much on the build version and operating system, so I can't show in one diagram how on a 2-processor AMD server we are at the level of 1 million transactions per second, and on a 4-processor server-at the level of 2.2 million transactions per second, but in general, this is true, the closer the software comes to the capabilities of the hardware, the stronger the difference between 16-channel and 24-channel memory access at the host level.
In relational databases, the issue of table access time is always acute, and to take into account the processing power of processors, we use MariaDB 10.3 with a test table containing 100 million records.
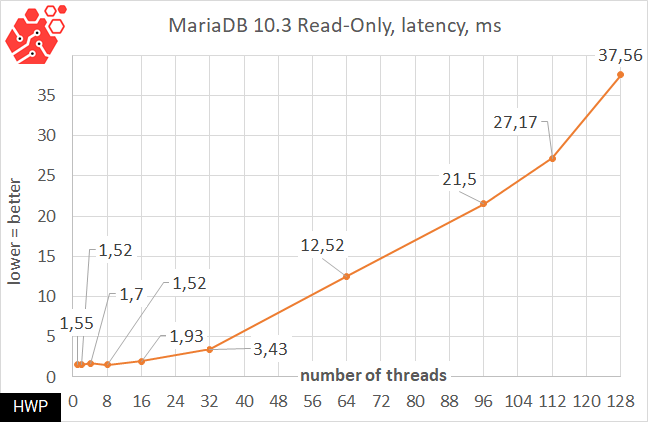
And it is quite natural that the server can easily cope with the read load - we can say that up to 32 simultaneous read requests to such a large table are processed with a delay of less than 4 ms, and up to 32 threads-in general, in one and a half milliseconds. Practically, of course, the entire test table can fit in the machine's memory, but in practice, the speed will rest on the disk subsystem.
Storage Subsystem
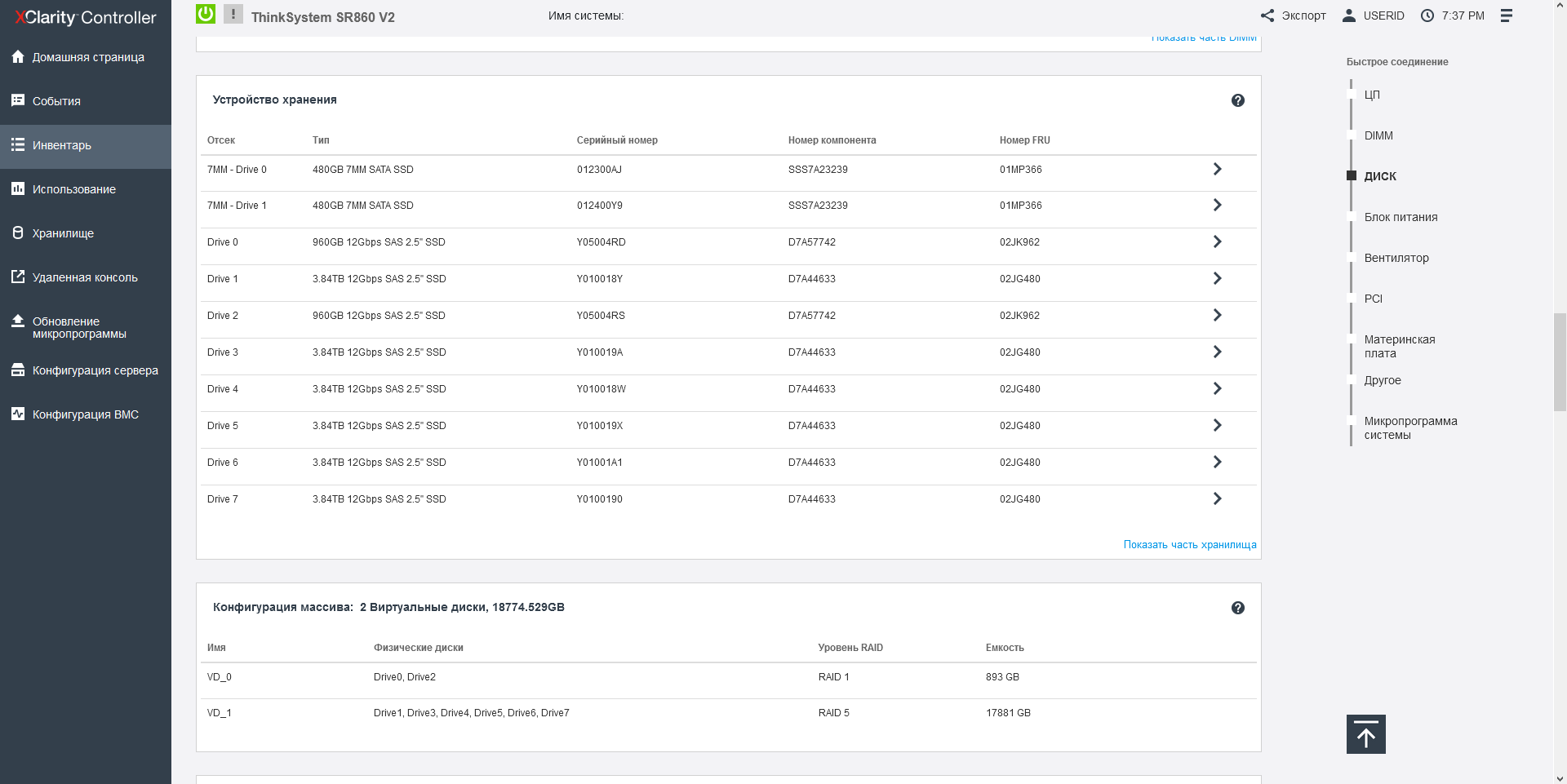
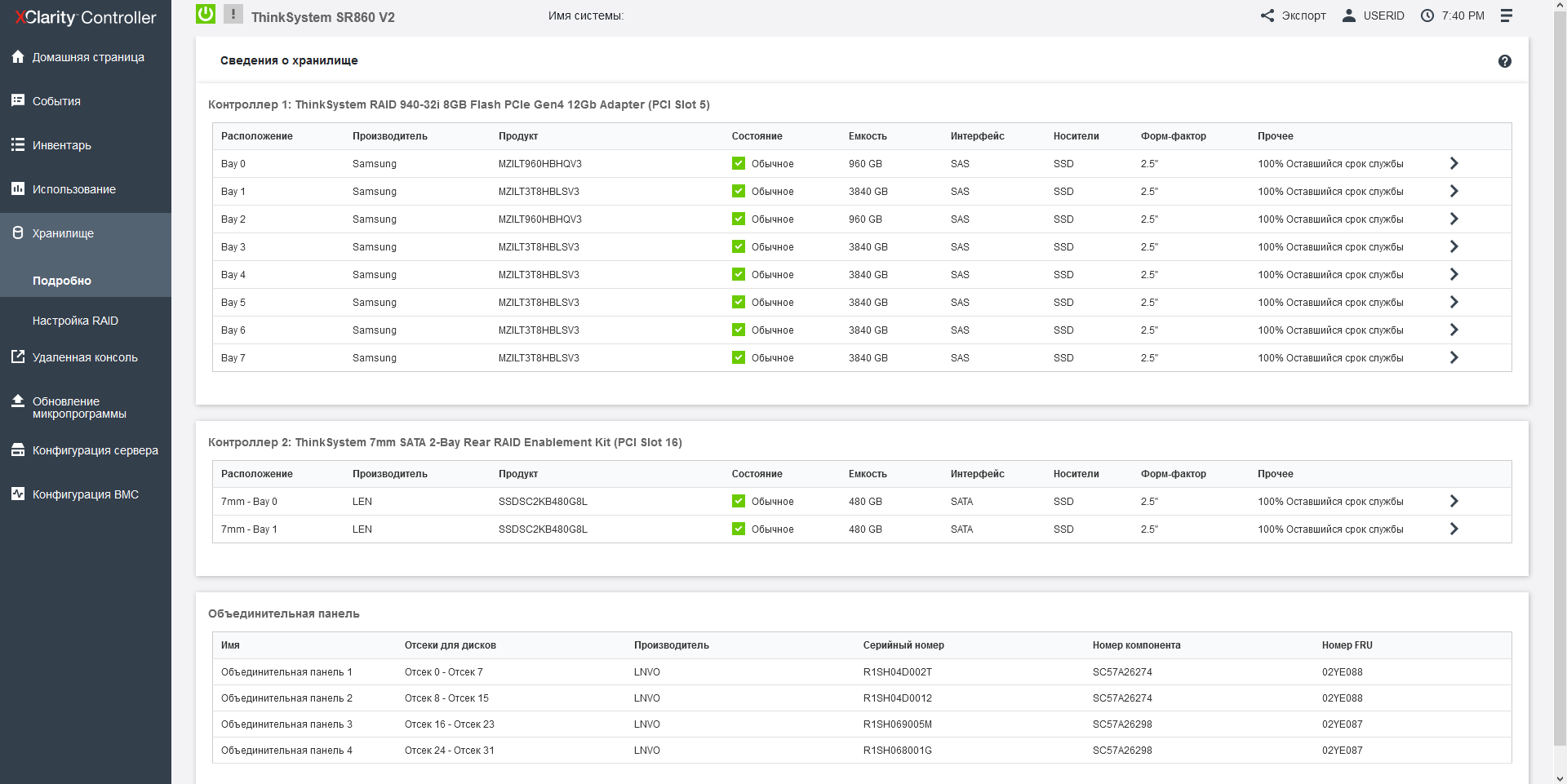
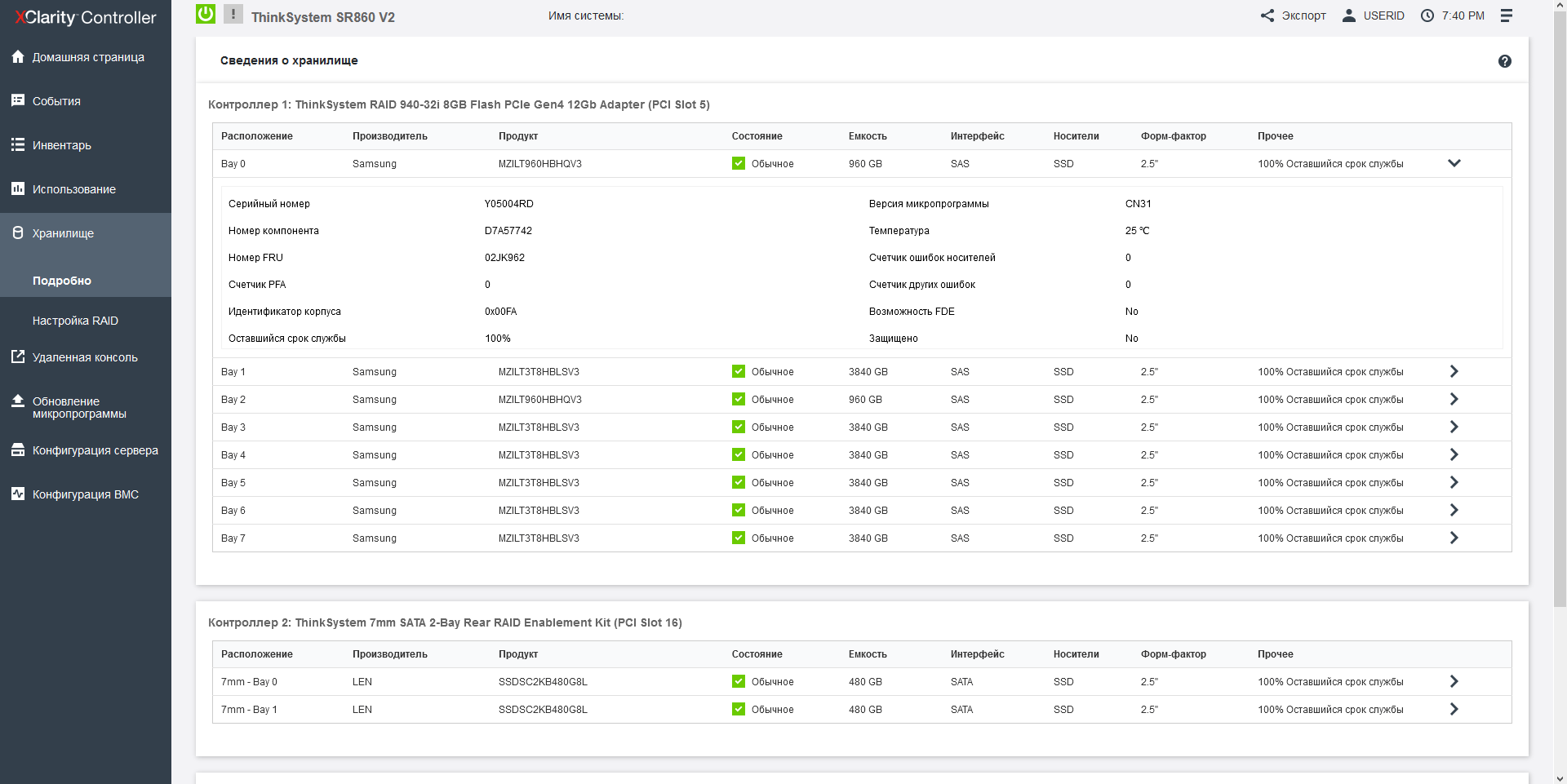
In total, the server has 48 slots for installing a 2.5-inch HDD/SSD with a thickness of 15 mm on the front side, as well as two SSDs with a thickness of 7 mm on the back. As a rule, these 7-mm disks are used to boot a full-fledged operating system or hypervisor, and if you need, you can install both SATA and NVMe models there, or you can choose a pair of internal M. 2 drives instead of or together with a pair of 7-mm, installing the appropriate riser for this purpose. A pair of bootable disks (both SATA and M.2) can be combined into a RAID array.
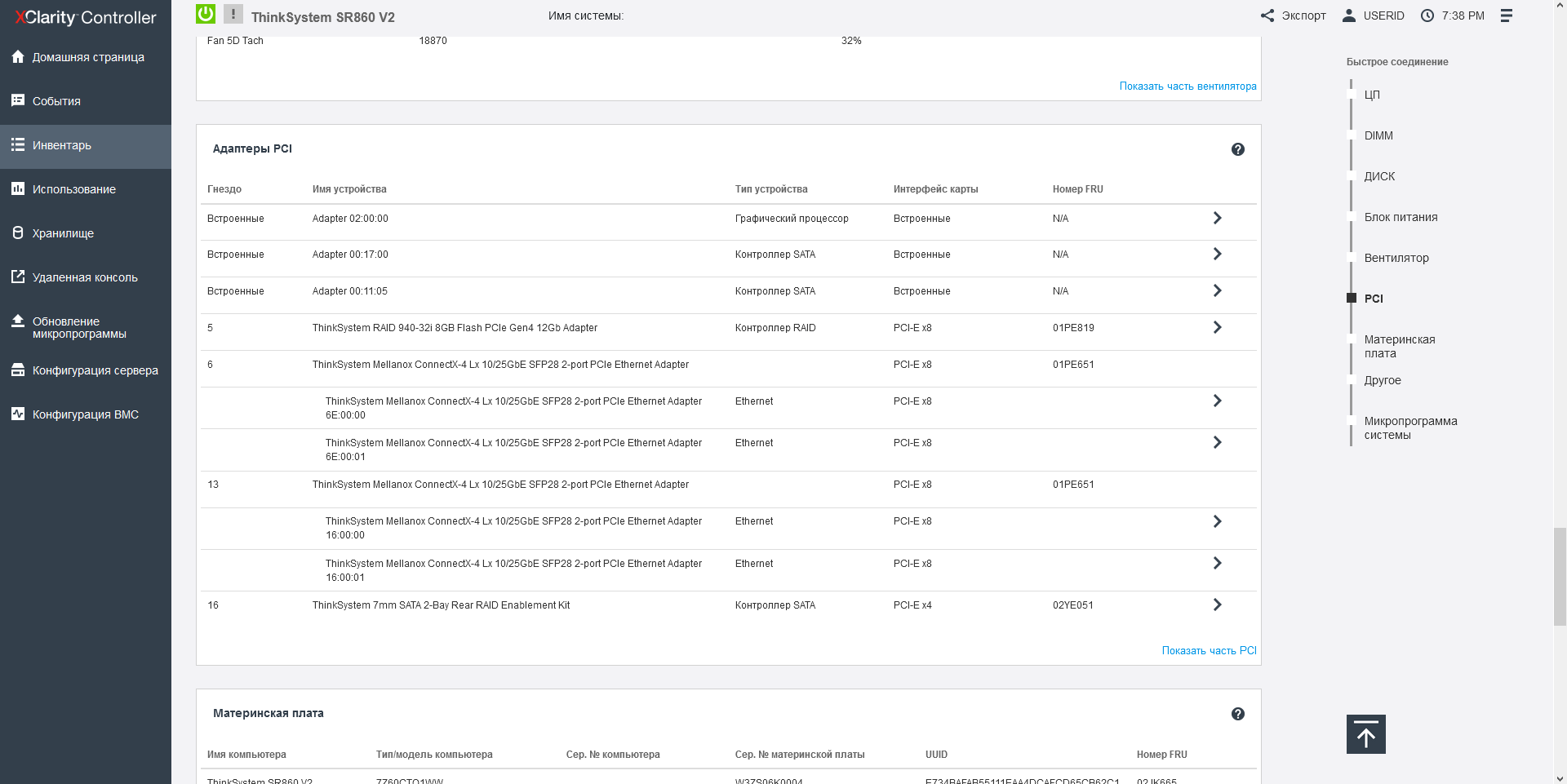
Front-end SSDs are grouped into 8-piece buckets, and when configured, you can use both SAS and NVMe drives with full bandwidth (each 4x disk has a 4x bus). In order to mix drives with SAS/SATA and NVMe interfaces in one system, Lenovo has developed universal Anybay backplanes for 8 disks, installed in the upper block of the front panel under the drives. Since the SAS, SATA, and NVMe ports are physically identical, the type of connection is determined by the cable and is carried out either to the SAS controller or to the connector near the processor. In one SR860V2 server, 3 Anybay backplanes can be installed, that is, the total maximum number of NVMe disks can be 24.
Up to 16 NVME SSDs can be connected directly to the processor (4 for each of the CPUs), and to install the remaining 8 NVME drives, you will need Lenovo 1610-8P adapters, each of which can be hung on 4 SSDs.

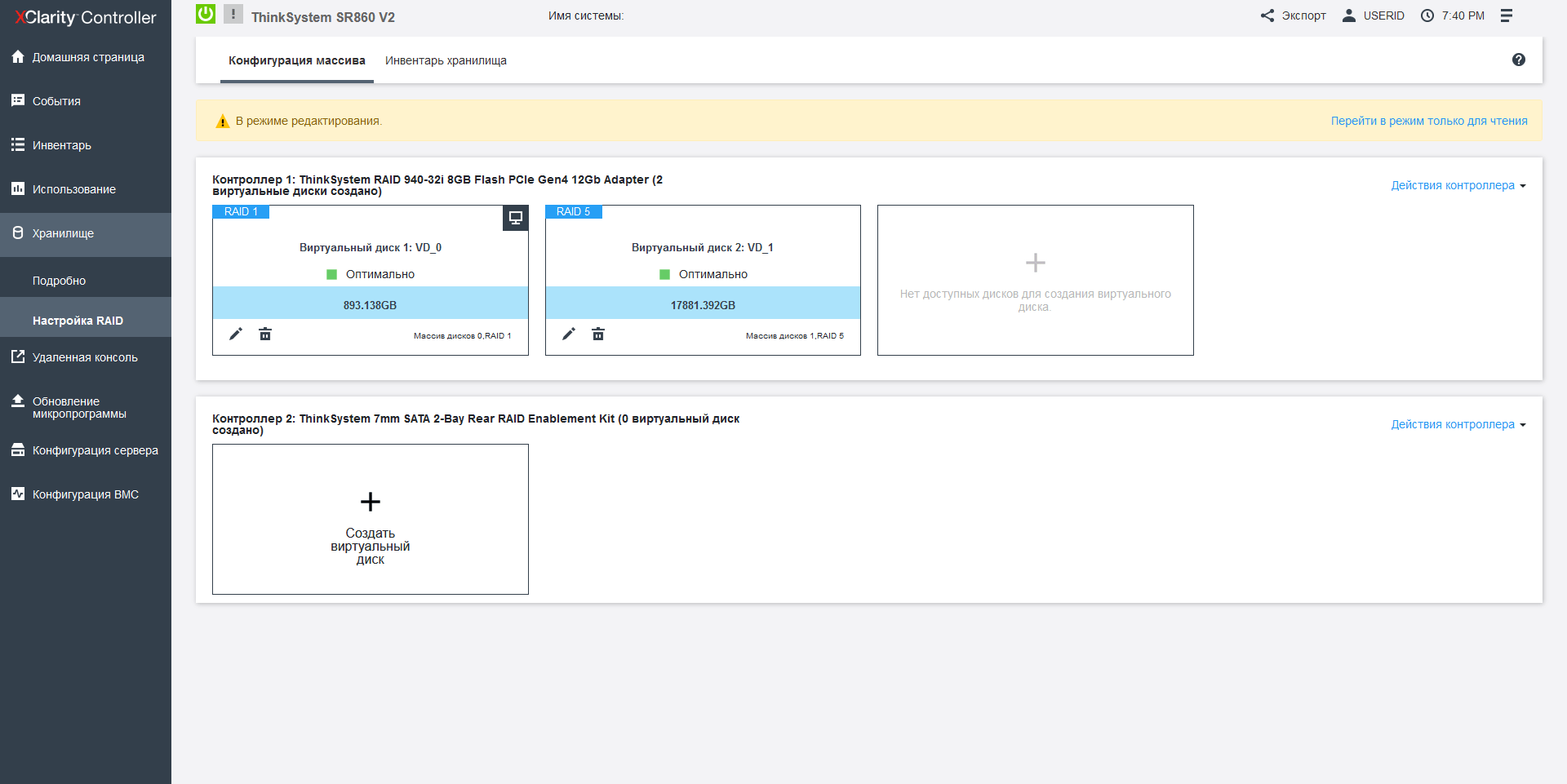
In the server case, space is allocated to accommodate 4 supercapacitors from various storage controllers, both with external and internal ports. In addition to the above-mentioned 1610-8p models for NVME drives, RAID / HBA adapters with a port density of up to 16x SAS-12 and a 32-port 940-32i RAID adapter with an impressive 8 GB cache are available. The RAID providers are LSI / Avago / Broadcom, and both simple and complex arrays of levels 50 and 60 are supported by default.
In the server case, space is allocated to accommodate 4 supercapacitors from various storage controllers, both with external and internal ports. In addition to the above-mentioned 1610-8p models for NVME drives, RAID / HBA adapters with a port density of up to 16x SAS-12 and a 32-port 940-32i RAID adapter with an impressive 8 GB cache are available. The RAID providers are LSI / Avago / Broadcom, and both simple and complex arrays of levels 50 and 60 are supported by default.
In our ElasticSearch test, the SR860 V2 server, unfortunately, did not achieve any heights:
$ esrally --distribution-version=7.6.0 --track=http_logs --challenge=append-no-conflicts-index-only --user-tag="Lenovo:SR860V2"
------------------------------------------------------
_______ __ _____
/ ____(_)___ ____ _/ / / ___/_________ ________
/ /_ / / __ \/ __ `/ / \__ \/ ___/ __ \/ ___/ _ \
/ __/ / / / / / /_/ / / ___/ / /__/ /_/ / / / __/
/_/ /_/_/ /_/\__,_/_/ /____/\___/\____/_/ \___/
------------------------------------------------------
| Metric | Task | Value | Unit |
|---------------------------------------------------------------:|-------------:|------------:|-------:|
| Cumulative indexing time of primary shards | | 302.233 | min |
| Min cumulative indexing time across primary shards | | 0 | min |
| Median cumulative indexing time across primary shards | | 2.86752 | min |
| Max cumulative indexing time across primary shards | | 44.2129 | min |
| Cumulative indexing throttle time of primary shards | | 0 | min |
| Min cumulative indexing throttle time across primary shards | | 0 | min |
| Median cumulative indexing throttle time across primary shards | | 0 | min |
| Max cumulative indexing throttle time across primary shards | | 0 | min |
| Cumulative merge time of primary shards | | 86.0147 | min |
| Cumulative merge count of primary shards | | 1891 | |
| Min cumulative merge time across primary shards | | 0 | min |
| Median cumulative merge time across primary shards | | 0.336142 | min |
| Max cumulative merge time across primary shards | | 16.0277 | min |
| Cumulative merge throttle time of primary shards | | 44.8813 | min |
| Min cumulative merge throttle time across primary shards | | 0 | min |
| Median cumulative merge throttle time across primary shards | | 0.0247833 | min |
| Max cumulative merge throttle time across primary shards | | 9.44482 | min |
| Cumulative refresh time of primary shards | | 7.15938 | min |
| Cumulative refresh count of primary shards | | 2528 | |
| Min cumulative refresh time across primary shards | | 3.33333e-05 | min |
| Median cumulative refresh time across primary shards | | 0.0824833 | min |
| Max cumulative refresh time across primary shards | | 0.979233 | min |
| Cumulative flush time of primary shards | | 3.01417 | min |
| Cumulative flush count of primary shards | | 115 | |
| Min cumulative flush time across primary shards | | 0 | min |
| Median cumulative flush time across primary shards | | 0.00926667 | min |
| Max cumulative flush time across primary shards | | 0.54535 | min |
| Total Young Gen GC | | 166.775 | s |
| Total Old Gen GC | | 21.47 | s |
| Store size | | 25.2233 | GB |
| Translog size | | 2.04891e-06 | GB |
| Heap used for segments | | 85.2323 | MB |
| Heap used for doc values | | 0.104988 | MB |
| Heap used for terms | | 77.6266 | MB |
| Heap used for norms | | 0.0402832 | MB |
| Heap used for points | | 0 | MB |
| Heap used for stored fields | | 7.46045 | MB |
| Segment count | | 660 | |
| Min Throughput | index-append | 179549 | docs/s |
| Median Throughput | index-append | 181855 | docs/s |
| Max Throughput | index-append | 183250 | docs/s |
| 50th percentile latency | index-append | 193.853 | ms |
| 90th percentile latency | index-append | 292.794 | ms |
| 99th percentile latency | index-append | 491.719 | ms |
| 99.9th percentile latency | index-append | 847.012 | ms |
| 99.99th percentile latency | index-append | 1013.85 | ms |
| 100th percentile latency | index-append | 1072.59 | ms |
| 50th percentile service time | index-append | 193.853 | ms |
| 90th percentile service time | index-append | 292.794 | ms |
| 99th percentile service time | index-append | 491.719 | ms |
| 99.9th percentile service time | index-append | 847.012 | ms |
| 99.99th percentile service time | index-append | 1013.85 | ms |
| 100th percentile service time | index-append | 1072.59 | ms |
| error rate | index-append | 0 | % |
ElasticSearch is the task that, in the case of the server in question, can be moved to separate virtual machines and shoved somewhere on the stack, allocating them well, 16, well, or 32 cores at most, and using the rest of the power for more resource-intensive tasks.
Network subsystem
The server offers several options for installing network cards: in a single OCP slot with a PCI Express 3.0 x16 interface, or in many standard PCIe slots. There are as many as 10 variants of boards installed in the OCP slot: from the 4-port 1-gigabit Broadcom 5719 and up to the 25-Gigabit top 2-port Mellanox ConnectX 6. In our case, the simplest solution from Broadcom was installed, and under VMware ESXi 7, this card was defined as a USB Ethernet adapter and refused to work, so we had to connect it through the high-speed adapters that the test machine was equipped with.
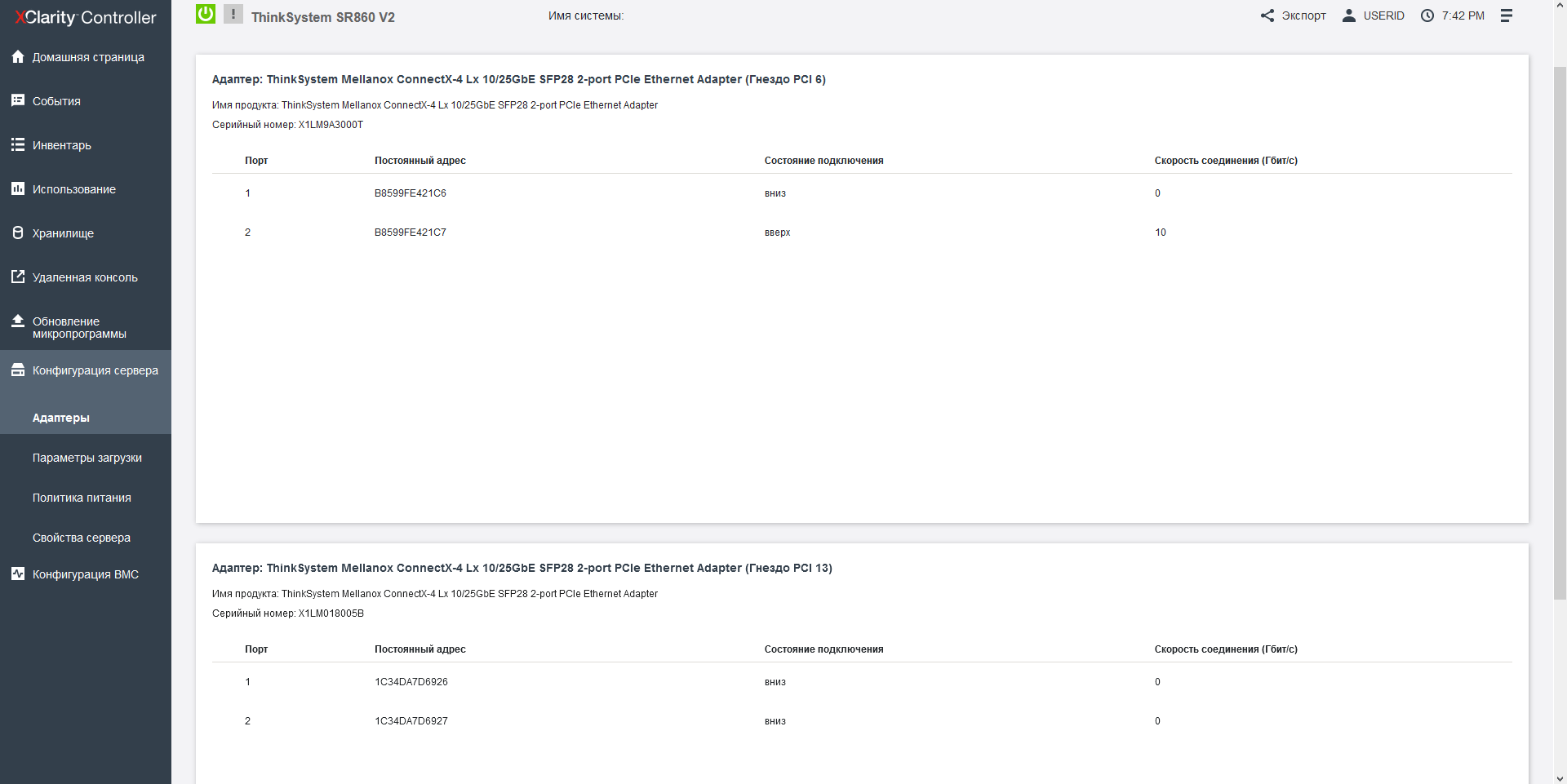
In standard PCIe slots, you can choose from almost everything that the industry has created: Lenovo has in its arsenal 4 different controllers for each of the speed thresholds: 100/200, 25 and 10 Gbit / s, and for 1-Gigabit connection as many as 5 controller options. In our case, 2 Mellanox Connect X-4 controllers were installed in the server, each with a pair of 25-gigabit ports, but for some reason there are no SmartNIC adapters in the server configurator, and today this is the newest thing that the industry offers.
GPU compatibility
As for the GPU, you can install a lot of adapters in the SR860 V2 server, but there is little choice: either 8 AI output adapters (Nvidia Tesla T4 with passive cooling), or 4 adapters for machine learning (Nvidia Tesla V100S with passive cooling). If you do not get hung up on the compatibility list, then the huge internal space allows you to install both ASIC and FPGA boards. To install the GPU, special risers are required, and you should also take care of the power reserve, although in this regard, the server has a complete order.
Power subsystem
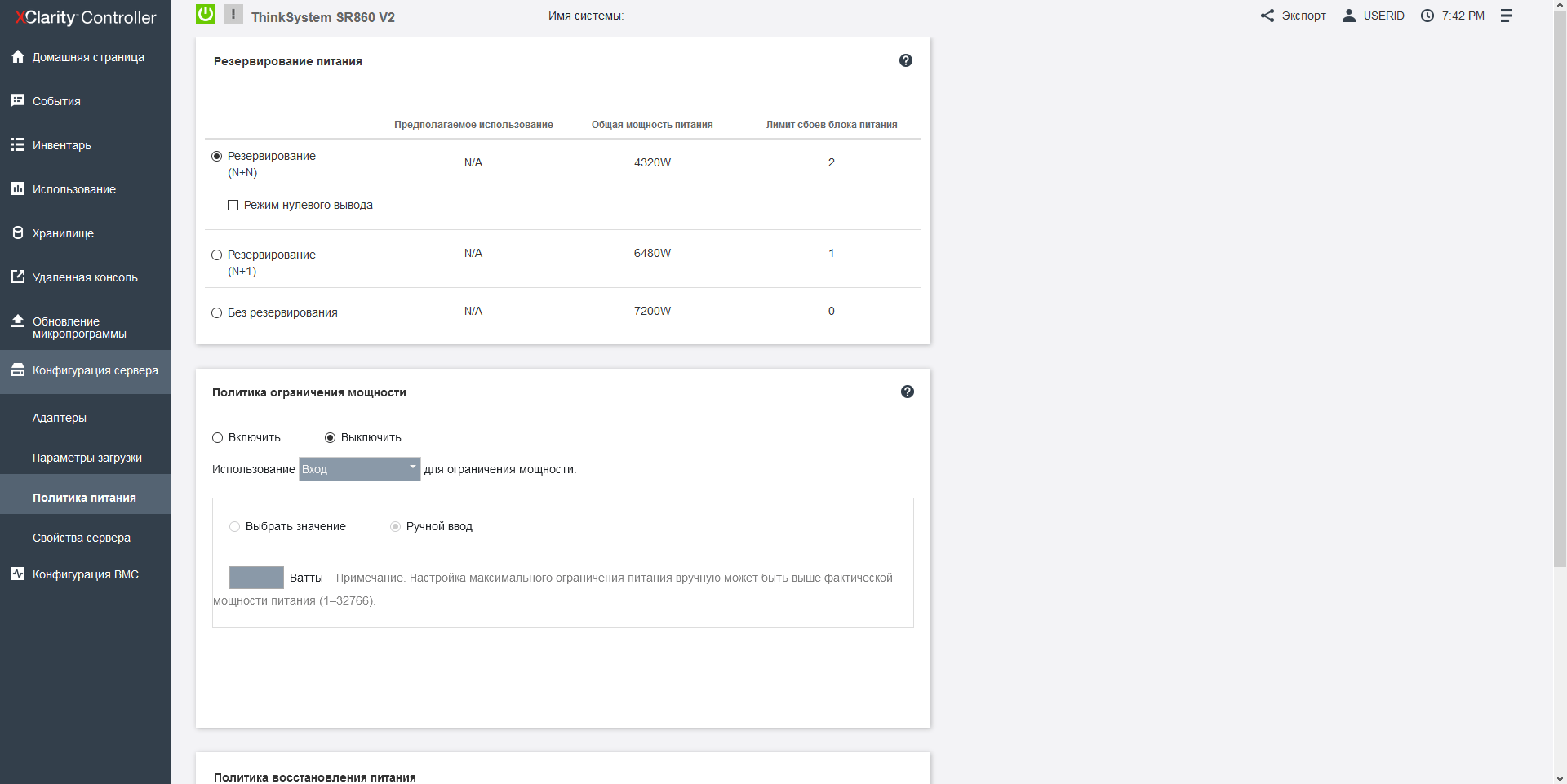
The Lenovo SR860v2 server has 4 power supplies of 1800 W each with an energy efficiency level of 80 Plus Platinum, which can operate in different modes: N+1, N+2 or without redundancy, providing a total power of up to 7.2 kW.
The server settings manager has the ability to limit the power that may be required if you need to rigidly fit into the power budget for the server rack.
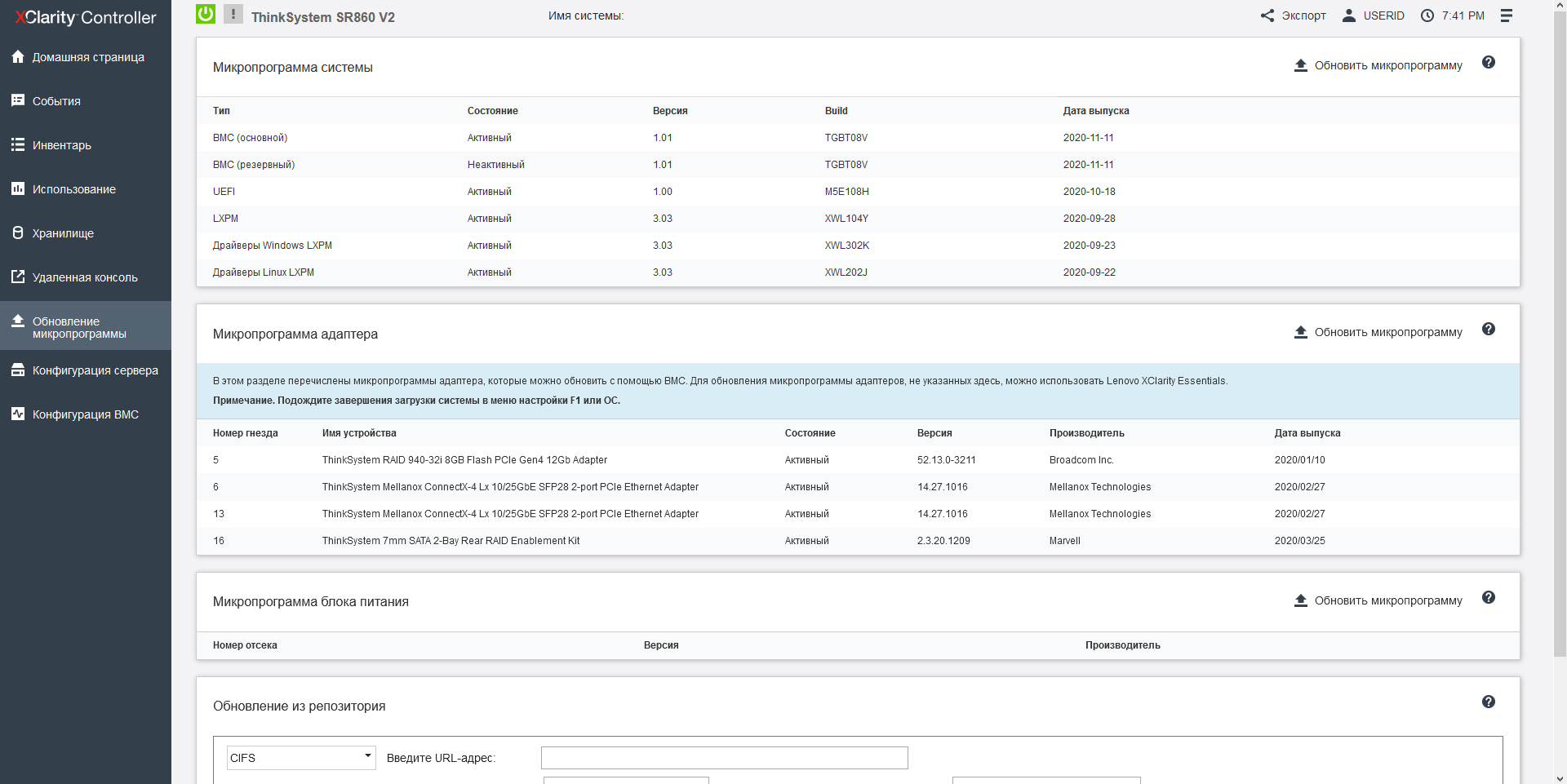
System monitoring and UEFI
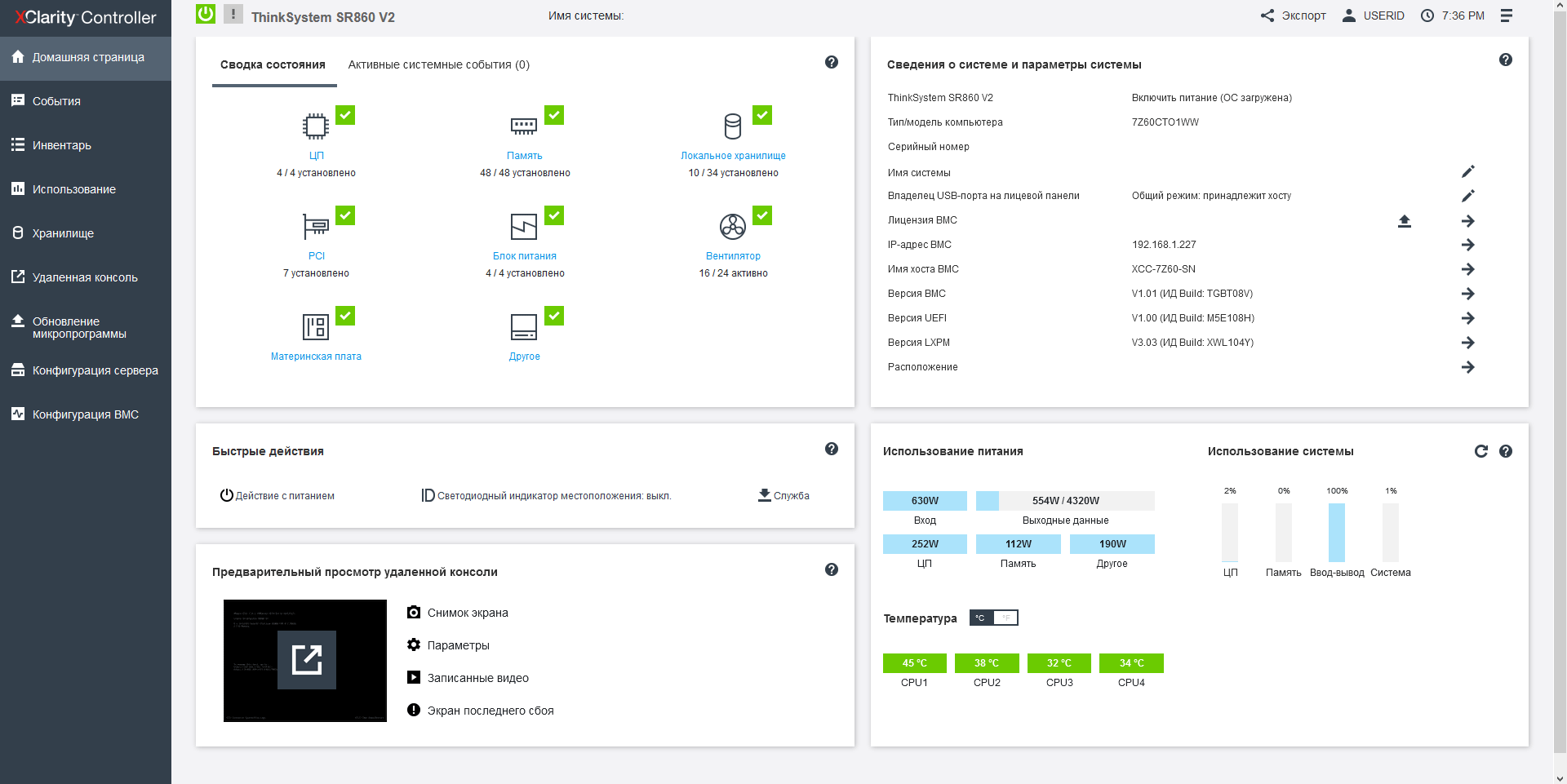
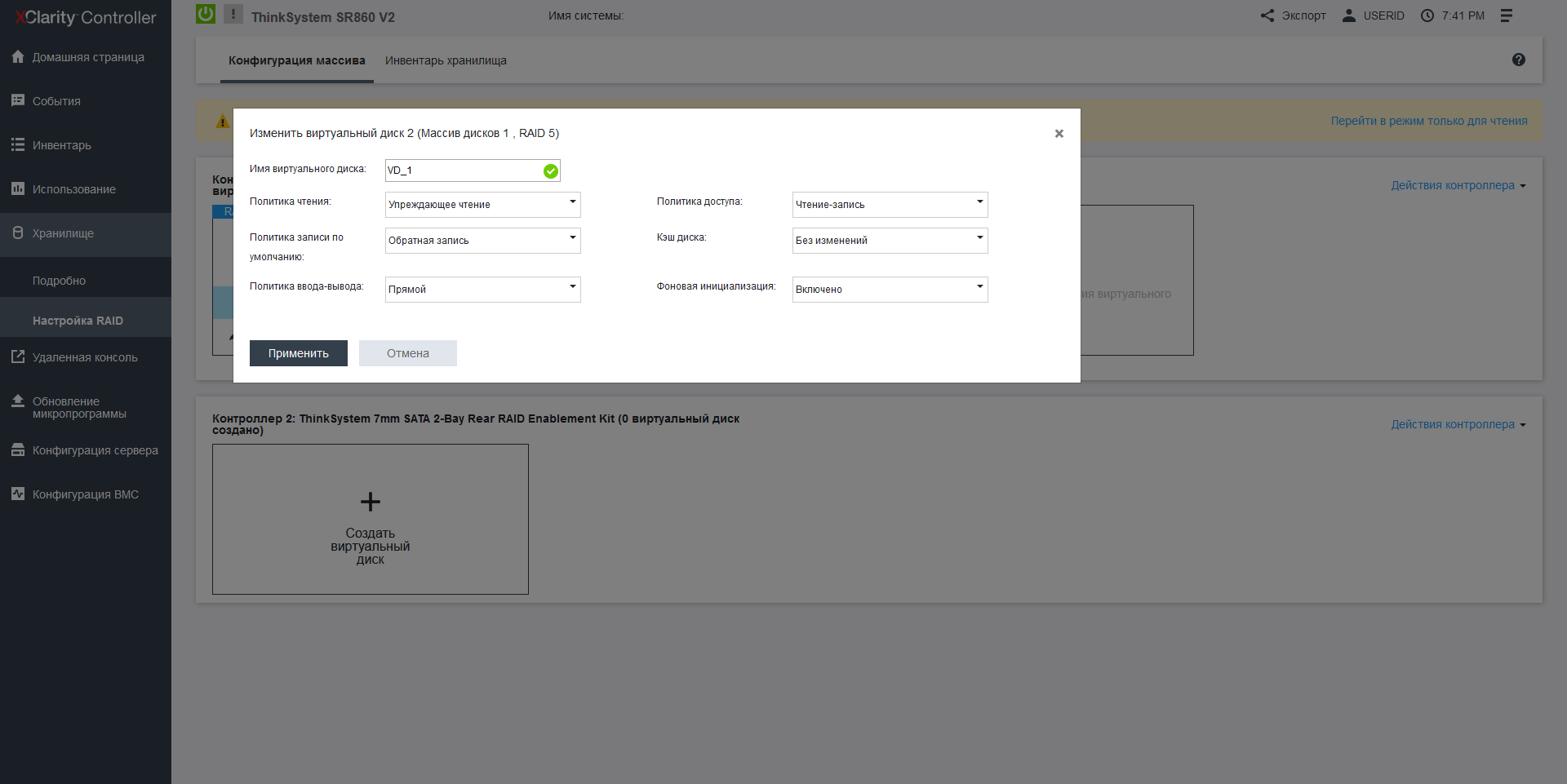
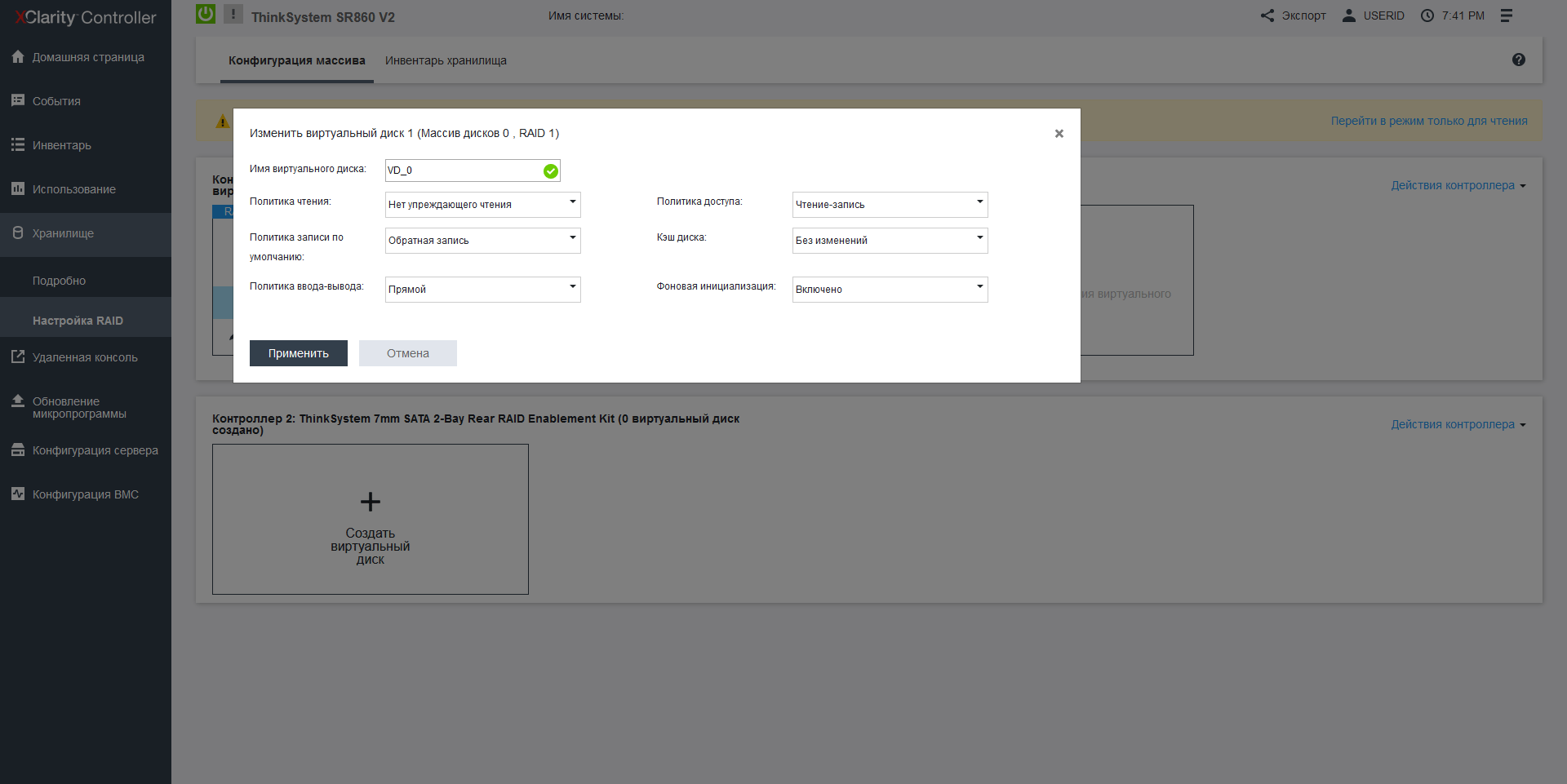
Lenovo SR860 V2 has a modern monitoring system with integration into the hypervisor. First, for On-Site situations, a retractable LCD screen is installed here, which displays the system status and the IP address of the XClarity web interface, in which RAID settings, functionality for updating firmware, and monitoring itself are collected in a single management system, as well as a convenient menu for selecting a bootable OS, which is easy to navigate if you have several operating systems with a UEFI bootloader. It is very interesting that the RAID type can be changed on the fly, without restarting the machine, that is, it is not necessary to install control software in the operating system.
For fans of charts and graphs, here in a beautiful HTML5 interface shows the power consumption of various components, and more importantly-the loading of subsystems. The console connection supports multi-user access and the use of the bootloader on the operator's computer.
The Lenovo SR860V2 server has a system for predicting hardware component failures, which allows you to identify a potentially faulty component even before it fails. At the same time, the messages/events/triggers of this system are a warranty service case, that is, a ready-to-break, but still working drive, you will be replaced under warranty. The fault prediction system is integrated into VMware vCenter and Microsoft System Center, supporting monitoring of processors, VRM power circuits, internal drives of all types, fans, power supplies, and RAID controllers, as well as ambient air temperatures, because the issue of cooling for such a heat-loaded machine is extremely relevant.
The only thing you can find fault with is a very long passage of UEFI POST-tests, especially when you first turn it on. But this is a payment for a huge amount of RAM that needs to be tested before starting.
Conclusions
Today, in large public and private companies, when designing infrastructure, the diversification of the processor architecture is considered, as we discussed in the article about the diversification of the CPU supplier. One of the tasks is the transition from the Power platforms to the more common x86, where sanctions risks are lower, maintenance personnel are paid lower, and software development is easier.
Lenovo SR860 V2 is just such a candidate for building an infrastructure with vertically scalable nodes, where unification, diversification and resistance to political risks are required.
What I liked
From a design point of view, I take my hat off to the developers who created the chassis, in which the processors are installed on top of each other, and above them there is also room for GPU/FPGA expansion cards. It is nice to see that after the transition of the x86 business from IBM to Lenovo, the latter continues to produce interesting design solutions with a convenient monitoring system. I would not be surprised if somewhere inside the server there was a sign with the name of the master, as it happens in expensive cars. At the same time, while maintaining objectivity, I have something to scold the developers for.
What I didn't like
In particular, I did not like that the built-in network card of the OCP format cannot work as a full-fledged network interface in VMware ESXi 7.01 (that is, it is not clear what it is needed for), perhaps this function will be supported in future software versions. I also consider it a waste to give the entire front panel for thick 15-mm drives, the use of which is justified in dual-controller storage, but not in servers.
And yet, regardless of my claims, I am pleased that the world of vertically scalable systems has not disappeared under the onslaught of cloud environments and universal unification, but continues to develop, offering enterprise users hardware platforms for the most resource-intensive tasks.
Michael Degtjarev (aka LIKE OFF)
23/03.2021













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}